-
DorisDB,ClickHouse,TiDB的对比与选型分析
系统对比
DorisDB ClickHouse TIDB 版本 DorisDB-SE-1.15.2 ClickHouse server version 21.6.5 revision 54448 TiDB-v5.1.0 TiDB Server Community Edition (dev) 定位 ROLAP
MPP 执行架构
支持物化视图(RollUp)
使用 Index 加速查询
向量化计算(AVX2 指令集)
稀疏索引ROLAP
MPP 架构的列存储库,多样化的表引擎
以有序存储为核心的完全列存储实现
并行扫磁盘上的数据块,降低单个查询的 latency
极致向量化计算
稀疏索引HTAP
行存储(TiKV 存储方式)
列存储(TiFlash 组件实现)语言层面 Front End: Java, Back End: C++ C++ TiDB: Go, TiKV: Rust, RocksDB: C++ 架构层面 Front End:
管理元数据
监督管理 BE 的上下线
解析 SQL,分发执行计划
协调数据导入
Back End:
接收并执行计算任务
存储数据,管理副本
执行 compact 任务Zookeeper:
执行分布式 DDL;
多副本之间的数据同步任务管理下发;
ClickHouse:
数据存储查询;
架构扁平化,可部署任意规模集群;TIDB 作为计算&调度层:
SQL 解析/分发/谓词下推到存储层;
集群信息收集,replica 管理等;
TiKV+RocksDB 作为数据存储层:
TiKV 实现了事务支持/Raft 协议/数据读写;
数据最终存放在 RocksDB;
TiFlash: 列存储,用来加速查询&支持 OLAP 相关需求;
TiSpark: 计算引擎,用来支持 OLAP 相关需求;系统安装&维护 成本低;
收费版本提供 DorisManager 工具来安装维护集群,免费版本需要手动安装;
看官方文档说:“DorisDB 是一个自治的系统,节点的上下线,集群扩缩容都可通过一条简单的 SQL 命令来完成,数据的自动 Reblance”;
看各种技术文提到 DorisDB 维护成本也是较低,但不清楚是否能达到官方文档中的效果和是否有各种异常出现;成本高
Clickhouse 需安装的组件较少,安装起来也较为简单;但集群不能自发感知机器拓扑变化,不能自动 Rebalance 数据,扩容/缩容/上下线分片、副本等都需要修改配置文件或执行 SQL 语句做数据迁移表变更的操作,有些时还需需要重启服务,维护成本高;成本中;
个人感觉 TiDB 的组件较多,
计算存储相关就有 TiDB,TiKV,TiFlash,TiSpark 等;
所以系统安装相对麻烦一点(需要安装的组件较多),对于扩容/缩容/升级等操作官方有提供 TiUP 组件,操作相对简单;监控&报警 收费版本中可使用 DorisManager 提供的控报警的功能;
免费版本可以通过 Prometheus+Grafana 进行监控报警;Clikckhouse 支持对接 Prometheus ,可以通过 Prometheus+Grafana 进行监控报警; 官方提供一套 Prometheus+Grafana 来实现监控报警的功能; 系统升级 可以滚动/平滑的升级,官方有相关升级文档 通过 yum 命令进行升级 通过 TiUP 实施在线/离线升级 集群能力 官方文档中说集群规模可扩展到数百个节点,
支持 10PB 级别的数据分析;官方提供案例集群规模在 300+,20 万亿+条的数据,
10PB+级别的数据;官方文档中有说最大支持 512 个节点,
集群最大容量 PB 级;SQL 语句支持 支持标准 SQL 语法 支持大部分的标准 SQL 语法
有部分非标准 SQL 语法,有一定学习成本支持标准 SQL 语法 SQL 数据类型 Number, String[1, 65533], Date, HyperLogLog, Bitmap, Array, Nested-Array Number, String[1, ∞], Date, Bitmap, Enum, UUID, IP, Tuple, Array, Nested Array, Map, Nested Type, AggregateFunction, Lambda Expression Number, String[1, ∞], Date, Blob, Binary, Enum, Set, Json Schema 变更 支持对 column/rollup/index 等进行增删改的操作; Distributed, Merge, MergeTree 等表引擎支持 Alter 语句,可以对 column/index 等进行增删改的操作;ALTER 操作会阻塞对表的所有读写操作; 支持对 column/index 进行增删改的操作; 函数支持 支持日期/地理/字符串/聚合/窗口/bitmap/hash/cast 等函数;
支持 UDF,但需要写 C++;支持函数较 DorisDB 丰富,复合数据类型的函数支持也很丰富,诸如:hasAny, hasAll 很是用;
支持 UDF,但需要写 C++;支持的函数种类也很多,但在 JSON/复合结构的函数支持上一般;
暂不支持 UDF;数据模型 明细模型,聚合模型,更新模型(允许定义 UNIQUE KEY,导入数据时需要将所有字段补全才能够完成更新操作) 多样的表引擎提供了多样的数据聚合&分析模型 https://clickhouse.tech/docs/en/engines/table-engines/ TiFlash:列存储,TiSpark: 事务支持 每个导入任务都是一个事务 没有完整的事务支持 支持分布式事务,提供乐观事务与悲观事务两种事务模型 写入支持 支持从 Mysql, Hive, HDFS, S3, Local Disk, Kafka 等系统拉取数据;
支持通过 Spark, Flink, DataX, Insert into table select … 等方式写入数据;
支持 CSV、ORCFile、Parquet、Json 等文件格式;支持从 PostgreSQL, Mysql, Hive, HDFS, Kafka, Local Disk, 等系统拉取数据;
支持通过 Spark,Flink,Insert into table select …等方式写入数据;
支持 CSV, TSV, Json, Protobuf, Avro, Parquet, ORC, XML…等数据格式;支持从 Mysql, CSV, SQL 文件导入到 TiDB;
支持通过 Load data…等方式写入数据;
TiDB Lightning 支持 Dumpling, CSV, Amazon Aurora Parquet 等数据格式;更新支持 支持 Insert/Insert into table select…语句;
不支持 update 语句,需要采用 Insert+Merge;支持 Insert/Insert into table select…语句;
支持 update 语句,通过语法 ALTER TABLE table_name UPDATE column1 = expr1 [, …] WHERE filter_expr 实现,更新相当于重建分区,较重操作,以异步方式执行;TiDB 支持 Insert/Insert into table select…语句;
TiDB 支持 Update 语句;
TiFlash 可以与 TiKV 数据保持一致,通过 Raft 实现时数据同步;删除支持 支持语句:DELETE FROM table_name [PARTITION partition_name] WHERE filter_expr 支持语句:ALTER TABLE [db.]table [ON CLUSTER cluster] DELETE WHERE filter_expr TiDB 支持 Delete 语句 查询支持 Select 语句基本符合 SQL92 标准,支持 inner join,outer join,semi join,anti join,cross join。在 inner join 条件里除了支持等值 join,还支持不等值 join, 为了性能考虑,推荐使用等值 join。其它 join 只支持等值 join。 有非标准查询语法,支持 Join 语句,详细看社区文档:
https://clickhouse.tech/docs/en/sql-reference/statements/select/SELECT 语句与 MySQL 完全兼容; 数据交换 外部表支持:Mysql, HDFS, ElasticSearch, Hive;
交互支持:Kafka, Flink, Spark, Hive, Http, Mysql wire protocol外部表支持:Mysql, HDFS, Http url, Jdbc, Odbc;
交互支持:Flink(通过 clickhouse-jdbc 实现), Spark, Http, Jdbc, Odbc, Native Tcp, Command line, Mysql wire protocol, SQL 可视化工具交互支持:通过 Flink,TiSpark 进行查询操作;
对外暴漏的是 SQL 层,可以通过 JDBC, Mysql wire protocol 进行读写;集群模式 Front End + Back End Zookeeper + Clickhouse TiDB + PD + TiKV + TiFlash + TiSpark 问题遗留 当前不支持 update 语句,2021.7 月的新版本会支持 optimize table $name final 性能不高,多表 join 性能一般 简短概括 Doris 依靠索引+Rollup+分区分桶等方案实现高效的 OLAP,支持明细查询;复合数据类型支持有限,维护成本低; Clickhouse 依靠列存储+向量化+分片+多样的表引擎实现高效 OLAP,支持明细查询;功能强大,维护成本高; Tidb 更多是满足了 TP 场景,对与 AP 支持不足,OLAP 能力弱于 Doris&Clickhouse,支持明细查询;官方目标是支持 100%TP 场景和 80%AP 场景,大数据量/复杂 AP 场景通过 TiSpark 解决,维护成本较低; 综合对比 DorisDB 和 Clickhouse 都是为 OLAP 而设计的系统,DorisDB 在系统运维等方面十分方便,但相对 Clickhouse 在对复合数据类型支持上不够,暂不支持 Update 操作,在数据模型支持上也稍弱于 Clickhouse,SQL 函数支持上没 ClickHouse 丰富; Clickhouse 集群拓扑变化,分片上下线等都无法自动感知并进行 Reblance,维护成本高,多表 join 性能不稳定,但从 OLAP 引擎功能来讲 Clickhouse 是三者中最强大的一个,且有一定 Update 能力(OLAP 本身不善长 Update 操作); TiDB 的 TP 能力三者最好,AP 能力较差,毕竟大家都说是分布式 Mysql,增/删/改/事务能力强,能同步 Mysql binlog,但 AP 能力更多依靠 TiFlash/TiSpark,查询聚合耗时较其他两者长且不可控,组件较多,学习安装成本感觉较 DorisDB 高一些; 实时人群圈选场景需求说明
- 画像本身是一张以
user_id为主键,标签为列名的大宽表; - 画像标签数据有大量的
Array,MAP,Array<Map>等复合类型; - 画像标签需要实时增/删,对存储要求是:支持实时的增/删/改列的
DDL语句; - 标签数据需实时增量的更新,对存储要求是:支持大数据量的实时
UPDATE语句; - 人群圈选需要实时对任意标签列实施高效的组合过滤操作;
功能选型
TIDB
-
优点:
- 支持实时高频的
UPDATE操作;
- 支持实时高频的
-
缺点:
-
复合数据类型只支持
Set/JSON,对JSON来说,其内部结构不可见,Schema定义不够明确;
JSON这种半结构化数据格式是以Binary形式进行序列化存储的(JSON本身不能创建索引,需要反序列化解析后才能做过滤操作?),用于圈选性能较差,为JSON定义的函数不够丰富,且无法通过自定义函数来补充; -
数据写入当前好想只能通过
Insert Into语句,性能一般,不支持直接导入JSON数据;TiDB有DM工具,但只能实时同步Mysql Binlog,缺少与多种其他存储介质的数据交换功能;Spark/Flink的Sink Connector好像没有,可能需要自己手动实现; -
缺少和
Hadoop生态圈的交互以及数据同步组件,可能需要通过Jdbc或TiKV API接口实现;
-
-
其他:
- 读数据有
TiKV Client Java Api,Flink Source Connector是通过这个包自己定制直接读取TiKV数据的,可以做一些Filter Push Down;
- 读数据有
DorisDB
-
优点:
- 集群易维护;
- 支持
Array这种复合结构(当前只明细模型可用); - 多表关联查询性能良好;
-
缺点:
-
不开源,
DorisDB源码全都看不到,社区活跃度较ClickHouse差; -
支持复合数据类型不够,遇到
Array,Map或Array<Map>类型的标签需要打成宽表或拆表(多表Join性能良好); -
当前不支持
UPDATE操作, 需要通过INSERT OVERWRITE模拟更新操作(官方说是 7 月版本会支持UPDATE); -
当前只能在
Duplicate Table中定义Array类型,而圈选功能需要选择更新/聚合模型,这使得Array类型标签必须拆分到新表中,不太能满足圈人的功能需求;
-
-
其他:
-
发现一个比较怪的问题,
Apache Doris和DorisDB感觉上有分歧?按道理Apache Doris和DorisDB标准版应该是同一个产品定位吧,两者间的的Flink Connector实现代码差异较大,内置的UDF函数也各不相同,源码层面二者还是有一定差别的; -
Apache Doris暂时不支持符合结构数据,如:Array,Map等;
-
ClickHouse
-
优点:
-
支持
UPDATE操作(但性能一般,不如TiDB,可以用INSERT OVERWRITE模拟); -
有多样的表引擎和
SQL函数; -
支持多样的复合数据类型
Array,Map,Nested Type(但尝试写JSON数据到类型为Array<Nested>列时失败,可能是写入方法问题?); -
OLAP系统,查询性能较好;
-
-
缺点:
- 集群维护成本高;
- 多表
Join性能不稳定; - 非标准
SQL,有学习成本; - 每个表都需要手动分区分片,在维护的表较多时,日常维护成本昂贵;
-
其他:
- 当前工程用的开源协议是
Apache License Version 2.0; - 源码没贡献到
Apache社区,项目规划走向被俄罗斯团队把控;
- 当前工程用的开源协议是
功能选型
- 结论:
从功能角度出发更倾向于选择
ClickHouse; - 原因:
ClickHouse和DorisDB在做OLAP的性能和功能上高于TiDB;DorisDB的主要问题是对复合数据类型的支持不够(比如Array),这使得很多是Array类型的列必须进行拆表操作,业务成本高,增加了标签数据写入和查询等业务实现的复杂度;Update这个必须的Feature功能尚未看到;函数支持没ClickHouse丰富,在做查询时有些过滤规则没办法实现(比如:Array hasAny/hasAll);TiDB对复合数据类型的支持不够,只有Set,JSON这种复合结构,与Hadoop生态或其他外部存储结合度不高,数据的导入导出不够方便,支持导入的数据类型也不够丰富,使用上不太方便;函数支持上没ClickHouse丰富,没办法做Array hasAny/hasAll等操作;另外TiDB的查询性能不保证满足需求,需做测试;ClickHouse从功能角度来讲是最能满足用户圈选需求的系统,唯一的问题是维护成本较高,当前国内已有公司将Clickhouse应用到了画像场景;
性能测试
- 机器配置
ClickHouse TiDB(No TiFlash) Linux 版本 CentOS Linux release 7.2.1511 CentOS Linux release 7.9.2009 CPU QEMU Virtual CPU version (cpu64-rhel6) Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz CPU 核数 8C 8C CPU 线程数 8 8 内存大小 8G 32G 磁盘大小 1T 1T - SQL 语句
-- 表`user_profile_a`数据量:4528641条 -- 表`user_profile_b`数据量:12836360条 -- SQL-1: 基本数据类型的组合过滤 select count(*) from user_profile_b where channel_type = 'nature' and user_type = 2 and lang = 'zh_CN' and region = 'CHN' and country = 'CHN' and gender = 0; -- SQL-2 过滤double类型数值,通过Math.random() 为每条测试数据随机生成一个score select count(*) from user_profile_ where score > 0.2; -- SQL-3: 数组类型的过滤 select count() from user_profile_b where hasAny(user_watch_list, ['TSLA']); -- Clickhouse select count(*) from user_profile_b where JSON_CONTAINS(user_watch_list, '"TSLA"', '$'); -- TIDB -- SQL-4: 组合SQL-1, SQL-3的所有条件过滤 select count() from user_profile_b where channel_type = 'nature' and user_type = 2 and lang = 'zh_CN' and region = 'CHN' and country = 'CHN' and gender = 0 and hasAny(user_watch_list, ['TSLA']); -- ClickHouse select count(*) from user_profile_b where channel_type = 'nature' and user_type = 2 and lang = 'zh_CN' and region = 'CHN' and country = 'CHN' and gender = 0 and JSON_CONTAINS(user_watch_list, '"TSLA"', '$'); -- TiDB -- SQL-5: Join两张表,基本数据类型过滤条件 select count(*) from user_profile_b b, user_profile_a a where a.uuid = b.uuid and a.channel_type = 'nature' and a.user_type = 2 and b.lang = 'zh_CN' and b.region = 'CHN' and b.country = 'CHN' and b.gender = 0; -- SQL-6: Join两张表,带有Array类型的过滤条件 select count() from user_profile_b b, user_profile_a a where a.uuid = b.uuid and a.channel_type = 'nature' and a.user_type = 2 and b.lang = 'zh_CN' and b.region = 'CHN' and b.country = 'CHN' and b.gender = 0 and hasAny(a.user_watch_list, ['TSLA']); -- ClickHouse select count(*) from user_profile_b b, user_profile_a a where a.uuid = b.uuid and a.channel_type = 'nature' and a.user_type = 2 and b.lang = 'zh_CN' and b.region = 'CHN' and b.country = 'CHN' and b.gender = 0 and JSON_CONTAINS(a.user_watch_list, '"TSLA"', '$'); -- TiDB- 查询性能对比测试
ClickHouse TiDB(No TiFlash) Explain SQL-1 0.069s 1.695s 单表简单数据类型的条件组合查询 SQL-2 0.029s 1.113s 单表 Double类型数据的条件查询SQL-3 1.732s 30.935s TiDB官方文档说:”使用Binary格式进行序列化,对JSON的内部字段的查询、解析加快”,但从测试结果来看与CK相差较多SQL-4 0.229s 1.142s 应该有做 SQL优化:过滤简单数据类型的条件前置,减少需过滤Array条件的数据量,查询性能较SQL-3提升不少SQL-5 0.626s 0.536s 两张表 Join情况下TiDB要略好于CK,看来CK多表Join性能确实不太好?SQL-6 1.243s 0.880s 两张表 Join情况下TiDB要略好于CK,看来CK多表Join性能确实不太好?- 性能测试使用的都是单节点的机器,因某些原因未能在同样的软硬件基础上做性能测试;
- 此处没有将
DorisDB纳入对比,一方面是因为DorisDB满足不了画像场景的业务需求,比如对Array等复合类型支持不够,另一方面和DorisDB的工作人员沟通得到了一些性能方面的测试结论,自己假设了DorisDB的单表性能与ClickHouse相当,多表Join性能高于ClickHouse; - 本次性能测试场景并不完整,单从具体得到的结果来看,
ClickHouse在多表Join方面表现一般,若有多表做复杂Join或大表间做Join操作的需求,建议做更多具体的性能测试; - 从
Array查询优化来讲,在ClickHouse中可以考虑将Array转Bitmap来优化查询;TiDB有TiFlash,但不太清楚如何处理Array这类复合类型,是否能满足性能需求; Insert into select语句的性能大都取决于Select,非特别大数据量需写入的情况下Insert耗时相对较少;ClickHouse的Delete,Update语句性能不高,这个需要再做测试,或用Insert语句替换;ClickHouse的optimize table $table final性能不高,1200W数据测试需要8s~14s时间,生产上使用该操作时最好单独周期执行,比如5min执行一次;
- 画像本身是一张以
-
Flink Streaming 的启动流程源码分析
前言
当前团队
Flink集群使用的版本是1.7.2,采用per-job on yarn的运行模式,在近一年多的使用过程中碰到过多次内存相关的问题,比如:beyond the 'PHYSICAL' memory limit... Killing container.,总是感觉Flink Streaming在实际场景中的内存管理不够完美,会遇到各样的问题。在Flink 1.10版本 release 后,了解到该版本对TaskExecutor的内存配置做了重新设计,内心有想要去了解的冲动,然而看过社区文档后又有了更多的疑问,比如:TaskExecutor对应的 JVM 进程在启动时只会有-Xmx -Xms -XX:MaxDirectMemorySize三个内存相关参数是通过Flink计算得出的,新增的细粒度配置能给JVM这三个启动参数带来多少变化,或是只是一个方便内存计算的工具,对于对Flink内存较为了解的人来讲,通过旧的内存配置参数可以完成与新配置一样的效果。起初这篇文章计划写
Flink Streaming新/旧内存管理对比相关的内容,然而之后一段时间的业余精力被学习Rust消耗掉啦,6 月底才算有时间开篇;之前在阅读内存管理代码同时参杂读了些任务启动相关代码,所以就扩展下之前计划写的文章范围:以描述Flink Streaming整个启动流程为主,辅以内存分配/管理相关代码分析,阅读的Flink代码版本定为最新版本1.11.0。启动流程分析
启动流程: 从脚本提交到任务启动成功(
Flink-Web-Dashboard展示的任务状态为running)的整个流程,这个流程大致分为 3 个Stage:Client端:封装信息提交给Yarn,注册回调函数,轮训Job状态;Yarn分配Container启动AppMaster;AppMaster向Yarn申请资源启动TaskManager;
脚本示例:
// Per-job model flink run -m yarn-cluster -yn 24 -ys 2 -ytm 6g -ynm $job_name -c $main_class -d -yq ./$job_jar $paramsStreamGraph:
graph LR A(KafkaSource) --> B(MapOperator) B --> C(KafkaSink)[Client] 初始化 Job
// Client源码调用流程 [1] -> CliFrontend::main(String[] args) -> -> CliFrontend.parseParameters -> -> -> CliFrontend.run [2] -> UserMainClass::main(args: Array[String]) -> -> StreamExecutionEnvironment.getExecutionEnvironment -> -> StreamExecutionEnvironment.addSource -> -> DataStream.map -> -> DataStream.addSink [3] -> -> StreamExecutionEnvironment.execute -> -> -> StreamExecutionEnvironment.getStreamGraph -> -> -> -> StreamExecutionEnvironment.getStreamGraphGenerator -> -> -> -> StreamGraphGenerator.generate -> -> -> StreamExecutionEnvironment.execute(StreamGraph) -> -> -> -> StreamExecutionEnvironment.executeAsync -> -> -> -> -> DefaultExecutorServiceLoader.getExecutorFactory -> -> -> -> -> YarnJobClusterExecutorFactory.getExecutor -> -> -> -> -> YarnJobClusterExecutor.execute -> -> -> -> -> -> PipelineExecutorUtils::getJobGraph -> -> -> -> -> -> YarnClusterClientFactory.createClusterDescriptor [4] -> -> -> -> -> -> YarnClusterDescriptor.deployJobCluster -> -> -> -> -> -> -> YarnClusterDescriptor.deployInternal -> -> -> -> -> -> -> -> YarnClusterDescriptor.startAppMaster -> -> -> -> -> -> -> -> -> YarnClientImpl.submitApplication -> -> -> -> -> -> return CompletableFuture(new ClusterClientJobClientAdapter) -> -> -> -> -> [action] get `JobClient`, invoke `JobListener`, return `JobClient` -> -> -> -> [action] create `JobExecutionResult`, invoke `JobListener`, return `JobExecutionResult`1. 任务提交脚本会触发调用
org.apache.flink.client.cli.CliFrontend::main(String[] args),然后依次会执行:- 调用
EnvironmentInformation::logEnvironmentInfo加载 JVM 上线文环境; - 调用
GlobalConfiguration::loadConfiguration加载flink-conf.yaml配置信息; - 调用
CliFrontend.loadCustomCommandLines返回由GenericCLI,FlinkYarnSessionCli,DefaultCLI组成的List<CustomCommandLine>对象;FlinkYarnSessionCli中包含与yarn-cluster提交模式相关,可以通过Command命令提交的参数列表,如:-yid, -ynm, -yqu等等; - 调用
CliFrontend.new创建CliFrontend对象,利用[3]中的List<CustomCommandLine>获取有效可用于解析Command参数的Options列表,附值给成员变量customCommandLineOptions; - 调用
CliFrontend.parseParameters,匹配Command第一个参数run然后调用后序函数; -
调用
CliFrontend.run:- 解析
Command参数并封装为CommandLine对象; - 创建
ProgramOptions对象,是Job Command参数的封装类,持有CommandLine解析得来的参数; - 将
ProgramOptions传入PackagedProgram的构造函数,创建PackagedProgram对象,PackagedProgram负责具体具体调用UserJar的Main函数; - 执行
CliFrontend.executeProgram为任务执行上下文创建ExecutionEnvironmentFactory和StreamExecutionEnvironmentFactory对象,然后调用PackagedProgram.invokeInteractiveModeForExecution方法反射调用UserJar的main函数,执行具体任务逻辑;
- 解析
2.
UserJar的任务入口函数UserMainClass::main(args: Array[String])被调用后,会依次执行:- 调用
StreamExecutionEnvironment::getExecutionEnvironment创建StreamExecutionEnvironment和StreamContextEnvironment对象; - 调用
StreamExecutionEnvironment.addSource创建DataStreamSource对象,DataStreamSource对象内持有上下文环境中的StreamExecutionEnvironment和StreamTransformation对象,StreamTransformation中持有FlinkKafkaConsumer对象; - 调用
DataStream.map创建OneInputTransformation对象,其内部持有上游的StreamTransformation和上线文中的StreamExecutionEnvironment对象;最后将OneInputTransformation添加到StreamExecutionEnvironment的成员变量transformations列表中; - 调用
DataStream.addSink创建DataStreamSink对象,并将其添加到StreamExecutionEnvironment的成员变量transformations列表中; - 最后调用
StreamExecutionEnvironment.execute开始执行Job创建和任务提交;
3.
StreamExecutionEnvironment.execute在Client端的代码执行流程:-
调用
StreamExecutionEnvironment.getStreamGraph,先创建StreamGraphGenerator对象,然后调用StreamGraphGenerator.generate生成StreamGraph,生成StreamGraph流程如下:- 根据
Job和StreamExecutionEnvironment的配置以及上下文信息创建StreamGraph对象; - 遍历
StreamExecutionEnvironment.transformations,对每个StreamTransformation进行解析; - 从
StreamTransformation构建出StreamNode并存放到StreamGraph对象的成员变量Map<Integer, StreamNode> streamNodes中,一个StreamNode包含着一个FlinkOperator和这个Operator运行所需的参数/配置信息; - 调用
StreamGraph.addEdge,构建每个StreamNode的Input StreamEdge和Output StreamEdge对象,分别添加到StreamNode的成员变量inEdges和outEdges中; StreamEdge中包含它上下游StreamNode的Id值,数据传递规则ShuffleMode,StreamPartitioner等信息;
- 根据
- 调用
StreamExecutionEnvironment.execute(StreamGraph)执行任务提交流程并等待任务状态返回; - 在
StreamExecutionEnvironment.executeAsync内通过调用DefaultExecutorServiceLoader.getExecutorFactory检索jars 的META-INF.services目录,加载适合的ExecutorFactory(Java SPI),当前Job可用的是YarnJobClusterExecutorFactory; - 通过
YarnJobClusterExecutorFactory获取YarnJobClusterExecutor,然后执行YarnJobClusterExecutor.execute:- 调用
PipelineExecutorUtils.getJobGraph将StreamGraph转换为JobGraph,转换的重要逻辑在StreamingJobGraphGenerator.createJobGraph内,创建JobGraph的主要操作有:创建一个包有 32 位随机数的JobID;为Graph的每个顶点生成一个全局唯一的hash数(用户可通过DataStream.uid设置);生成JobVertex,它是Flink Task的上层抽象,包含Operators,invokableClass,SlotSharing,OperatorChaining等信息,存放在JobGraph的成员变量taskVertices中;此外还有,ExecutionConfig,SavepointConfig,JarPaths,Classpaths 等信息; - 调用
YarnClusterClientFactory.getClusterSpecification从Configuration中解析当前提交Job的JobManager/TaskManager的内存信息,用于校验Yarn Cluster是否有足够的资源分配给Job启动; - 调用
YarnClusterDescriptor.deployJobCluster执行具体的Job提交流程,返回一个ClusterClientJobClientAdapter对象,其内部通过RestClusterClient对象与Yarn Cluster通信,可获取Job状态或是执行一些其它操作;
- 调用
4. 调用
YarnClusterDescriptor.deployJobCluster执行Job提交:-
调用
YarnClusterDescriptor.deployInternal代码逻辑阻塞直到JobManager提交Yarn完成,逻辑如下:- 执行
Kerberos认证(如果有需要); - 校验上下文环境&配置是否满足
Job提交条件; - 查看是否存在合适的
yarn queue; - 校验/适配
ClusterSpecification(利用集群Yarn Container vCores/Memory的配置); - 调用
YarnClusterDescriptor.startAppMaster启动AppMaster(下文详解); - 将调用
startAppMaster返回的JobManager相关信息和applicationId写入Configuration;
- 执行
-
调用
YarnClusterDescriptor.startAppMaster:- 从
Configuration获取FileSystem配置信息,然后从plugins目录加载jars 初始化FileSystem实例; - 将
Zookeeper Namespace写入Configuration对象,可以通过high-availability.cluster-id配置,默认是applicationId; - 创建
YarnApplicationFileUploader对象,然后将log4j.properties,logback.xml,flink-conf.yaml,yarn-site.xml,UserJars,SystemJars,PluginsJars,JobGraph序列化,kerberos配置/认证等文件上传到hdfs:///user/$username/.flink/$applicationId/目录下; - 调用
JobManagerProcessUtils::processSpecFromConfigWithNewOptionToInterpretLegacyHeap,从Configuration获取Memory配置并计算出JobManager所在进程的Memory分配数值,最终以-Xmx, -Xms, -XX:MaxMetaspaceSize, -XX:MaxDirectMemorySize形式用到JVM进程启动;此外,Memory计算对旧版配置FLINK_JM_HEAP, jobmanager.heap.size, jobmanager.heap.mb做了兼容处理; - 调用
YarnClusterDescriptor.setupApplicationMasterContainer创建ContainerLaunchContext(启动Container所需的信息集合); - 将
ApplicationName,ContainerLaunchContext,Resource(向ResourceManager申请资源),CLASSPATH,Environment Variables,ApplicationType,yarn.application.node-label,yarn.tags等信息封装到ApplicationSubmissionContext;此时,ApplicationSubmissionContext就封装了ResourceManager启动ApplicationMaster所需的所有信息; - 为当前线程添加
提交任务失败的回调函数,用于在提交任务失败后kill Application & delete Files that have been uploaded to HDFS; - 调用
YarnClientImpl.submitApplication将任务提交给Yarn Client Api处理; - 轮训
YarnClientImpl.getApplicationReport等待提交任务提交成功(AppMaster正常启动),最后返回任务状态ApplicationReport;
- 从
YarnClientImpl.submitApplication内通过调用rmClient.submitApplication向Yarn Client提交Job:- 成员变量
YarnClientImpl.rmClient通过调用ConfiguredRMFailoverProxyProvider.getProxy获取到,YarnClientImpl.rmClient实例是ApplicationClientProtocolPBClientImpl的代理对象,其内部通过ProtoBuf + RpcEngine提交任务到Yarn Server端; - 在
Yarn Server端ClientRMService.submitApplication会收到所有来自Yarn Client的Job提交请求,执行后序的AppMaster启动操作;
[Server] 启动 JobManager
// Server端在Container中启动JobManager的流程 [1] -> YarnJobClusterEntrypoint::main(String[] args) -> -> EnvironmentInformation.logEnvironmentInfo -> -> SignalHandler.register -> -> JvmShutdownSafeguard.installAsShutdownHook -> -> YarnEntrypointUtils.logYarnEnvironmentInformation -> -> YarnEntrypointUtils.loadConfiguration -> -> ClusterEntrypoint::runClusterEntrypoint [2] -> -> -> YarnJobClusterEntrypoint.startCluster -> -> -> -> PluginUtils.createPluginManagerFromRootFolder -> -> -> -> ClusterEntrypoint.configureFileSystems -> -> -> -> ClusterEntrypoint.installSecurityContext -> -> -> -> ClusterEntrypoint.runCluster -> -> -> -> -> ClusterEntrypoint.initializeServices -> -> -> -> -> YarnJobClusterEntrypoint.createDispatcherResourceManagerComponentFactory -> -> -> -> -> DefaultDispatcherResourceManagerComponentFactory.create -> -> -> -> -> -> JobRestEndpointFactory.createRestEndpoint -> MiniDispatcherRestEndpoint.start -> -> -> -> -> -> YarnResourceManagerFactory.createResourceManager -> YarnResourceManager.start -> -> -> -> -> -> ZooKeeperUtils.createLeaderRetrievalService -> ZooKeeperLeaderRetrievalService.start -> -> -> -> -> -> DefaultDispatcherRunnerFactory.createDispatcherRunner -> -> -> -> -> -> -> JobDispatcherLeaderProcessFactoryFactory.createFactory -> -> -> -> -> -> -> DefaultDispatcherRunner::create -> -> -> -> -> -> -> -> DispatcherRunnerLeaderElectionLifecycleManager::createFor -> -> -> -> -> -> -> -> -> DispatcherRunnerLeaderElectionLifecycleManager::new -> ZooKeeperLeaderElectionService.start -> -> -> -> -> -> -> -> -> -> ZooKeeperLeaderElectionService.isLeader -> -> -> -> -> -> -> -> -> -> -> DefaultDispatcherRunner.grantLeadership -> -> -> -> -> -> -> -> -> -> -> -> DefaultDispatcherRunner.startNewDispatcherLeaderProcess -> -> -> -> -> -> -> -> -> -> -> -> -> JobDispatcherLeaderProcess.start -> AbstractDispatcherLeaderProcess.startInternal -> -> -> -> -> -> -> -> -> -> -> -> -> -> JobDispatcherLeaderProcess.onStart -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> DefaultDispatcherGatewayServiceFactory.create -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> JobDispatcherFactory.createDispatcher (create AkkaServer) -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> MiniDispatcher.start (call AkkaServer to execute job start) -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> Dispatcher.onStart -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> DefaultDispatcherBootstrap.initialize -> AbstractDispatcherBootstrap.launchRecoveredJobGraphs -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> Dispatcher.runRecoveredJob -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> Dispatcher.runJob // 调用链太长,从`Dispatcher.runJob`新建 [3] -> Dispatcher.runJob -> -> Dispatcher.createJobManagerRunner -> -> -> DefaultJobManagerRunnerFactory.createJobManagerRunner -> -> -> -> JobManagerRunnerImpl::new -> -> -> -> -> DefaultJobMasterServiceFactory.createJobMasterService -> -> -> -> -> -> JobMaster::new -> -> Dispatcher.startJobManagerRunner [4] -> -> -> JobManagerRunnerImpl.start -> -> -> -> ZooKeeperLeaderElectionService.start -> ZooKeeperLeaderElectionService.isLeader -> -> -> -> -> JobManagerRunnerImpl.grantLeadership -> JobManagerRunnerImpl.verifyJobSchedulingStatusAndStartJobManager -> JobManagerRunnerImpl.startJobMaster -> -> -> -> -> -> ZooKeeperRunningJobsRegistry.setJobRunning -> -> -> -> -> -> JobMaster.start -> -> -> -> -> -> -> JobMaster.startJobExecution -> -> -> -> -> -> -> -> JobMaster.setNewFencingToken -> -> -> -> -> -> -> -> JobMaster.startJobMasterServices -> -> -> -> -> -> -> -> JobMaster.resetAndStartScheduler -> -> -> -> -> -> -> -> -> DefaultJobManagerJobMetricGroupFactory.create -> -> -> -> -> -> -> -> -> JobMaster.createScheduler -> DefaultSchedulerFactory.createInstance -> DefaultScheduler::new -> -> -> -> -> -> -> -> -> JobMaster.startScheduling -> -> -> -> -> -> -> -> -> -> SchedulerBase.registerJobStatusListener -> -> -> -> -> -> -> -> -> -> SchedulerBase.startScheduling -> -> -> -> -> -> -> -> -> -> -> SchedulerBase.registerJobMetrics -> -> -> -> -> -> -> -> -> -> -> SchedulerBase.startAllOperatorCoordinators -> -> -> -> -> -> -> -> -> -> -> DefaultScheduler.startSchedulingInternal -> -> -> -> -> -> -> -> -> -> -> -> DefaultScheduler.prepareExecutionGraphForNgScheduling -> -> -> -> -> -> -> -> -> -> -> -> EagerSchedulingStrategy.startScheduling -> EagerSchedulingStrategy.allocateSlotsAndDeploy // stream job use EagerSchedulingStrategy as default Scheduler -> -> -> -> -> -> -> -> -> -> -> -> -> DefaultScheduler.allocateSlotsAndDeploy // explain ExecutionVertexID [5] -> -> -> -> -> -> -> -> -> -> -> -> -> -> DefaultScheduler.allocateSlots -> DefaultExecutionSlotAllocator.allocateSlotsFor -> DefaultExecutionSlotAllocator.allocateSlot -> NormalSlotProviderStrategy.allocateSlot -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> SchedulerImpl.allocateSlot -> SchedulerImpl.allocateSlotInternal -> SchedulerImpl.internalAllocateSlot -> SchedulerImpl.allocateSingleSlot -> SchedulerImpl.requestNewAllocatedSlot -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> SlotPoolImpl.requestNewAllocatedBatchSlot -> SlotPoolImpl.requestNewAllocatedSlotInternal -> SlotPoolImpl.requestSlotFromResourceManager -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> ResourceManager.requestSlot -> SlotManagerImpl.registerSlotRequest -> SlotManagerImpl.internalRequestSlot -> SlotManagerImpl.fulfillPendingSlotRequestWithPendingTaskManagerSlot -> SlotManagerImpl.allocateResource -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> ResourceActionsImpl.allocateResource -> YarnResourceManager.startNewWorker -> YarnResourceManager.requestYarnContainer -> AMRMClientAsyncImpl.addContainerRequest [6] -> -> -> -> -> -> -> -> -> -> -> -> -> -> DefaultScheduler.waitForAllSlotsAndDeploy -> DefaultScheduler.deployAll -> DefaultScheduler.deployOrHandleError -> DefaultScheduler.deployTaskSafe -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> DefaultExecutionVertexOperations.deploy -> ExecutionVertex.deploy -> Execution.deploy -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> TaskDeploymentDescriptorFactory.createDeploymentDescriptor -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> RpcTaskManagerGateway.submitTask -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> -> TaskExecutor.submitTask [invoke TaskExecutor via RPC which created by calling JobMaster.registerTaskManager]1. 在
Per-job模式下,AppMaster进程的启动入口是YarnJobClusterEntrypoint.main:- 调用
EnvironmentInformation::logEnvironmentInfo打印环境变量信息; - 调用
SignalHandler::register注册TERM, HUP, INT等终止/退出信号处理(例如:kill); - 从
System::getEnv获取变量PWD,该目录为进程的启动目录,目录下包含进程启动所需的jar, config, job.graph, launch_container.sh等文件(通过ln创建的链接文件),PWD目录位置:${yarn.nodemanager.local-dirs}/usercache/hadoop/appcache/${applicationId}/${containerId}; - 调用
YarnEntrypointUtils::logYarnEnvironmentInformation打印Yarn相关信息; - 调用
YarnEntrypointUtils.loadConfiguration从flink-conf.yaml和System.env构建Configuration对象; - 创建
YarnJobClusterEntrypoint对象,并为当前进程添加shutDownHook(在进程退出前进行删除本地文件的操作); - 调用
ClusterEntrypoint::runClusterEntrypoint,函数内部通过调用YarnJobClusterEntrypoint.startCluster做AppMaster启动操作,然后为YarnJobClusterEntrypoint对象注册了监控Termination的回调函数,用于打印进程结束的exit code等信息;
2. 调用
YarnJobClusterEntrypoint.startCluster,依次执行:- 调用
PluginUtils::createPluginManagerFromRootFolder,将plugin的name, jars填充到PluginDescriptor,然后将PluginDescriptor和委托给parent of plugin.classLoader加载的包名列表封装到DefaultPluginManager; - 调用
ClusterEntrypoint.configureFileSystems内部通过Java SPI去加载并初始化所有jars(包括common/plugin jars)的META-INF/services/目录下的FileSystemFactory服务; - 调用
ClusterEntrypoint.installSecurityContext,创建ZooKeeperModule, HadoopModule, JaasModule和HadoopSecurityContext对象并存放在SecurityUtils的成员变量,然后通过创建的HadoopSecurityContext对象触发执行ClusterEntrypoint.runCluster;从代码阅读来看:installSecurityContext的目的在于向运行环境添加必要的用户权限和环境变量配置; ClusterEntrypoint.runCluster执行流程:- 调用
ClusterEntrypoint.initializeServices初始化多个服务模块;commonRpcService:AkkaRpc服务,处理本地和远程的服务调用请求;haServices:ZooKeeperHaServices服务,处理与zookeeper的交互请求,如JobManager/ResourceManager等组件的leader选举;blobServer:处理Job BLOB文件的/上传/下载/清除等操作,BLOB包括Jars,RPC消息等内容;heartbeatServices:管理Job各组件的心跳服务;metricRegistry:监控指标注册,持有Job各监控指标和MetricReporters 信息;processMetricGroup:系统/进程监控指标组,包含CPU,Memory,GC,ClassLoader,Network,Swap等监控指标;archivedExecutionGraphStore:用于保存序列化的ExecutionGraph?
- 调用
YarnJobClusterEntrypoint.createDispatcherResourceManagerComponentFactory创建工厂对象DefaultDispatcherResourceManagerComponentFactory,工厂对象用于创建DispatcherResourceManagerComponent对象,该对象的创建过程是Job启动的核心逻辑所在;另外提一下,FileJobGraphRetriever将本地文件job.graph反序列化为JobGraph; DefaultDispatcherResourceManagerComponentFactory.create执行流程:- 创建并启动
Flink-Web-Dashboard的Rest接口服务WebMonitorEndpoint; - 创建并启动
YarnResourceManager以及其内部服务SlotManager,负责Job的资源管理,如:申请/释放/记录; - 创建并启动
MiniDispatcher,在Dispatcher启动过程中会创建JobManager线程完成任务的启动; - 向 ZooKeeper 注册
ResourceManager,Dispatcher的监听协调服务,用于服务的容错恢复,通过在Zookeeper中保持了一个锁文件来协调服务; - 上述
WebMonitorEndpoint, YarnResourceManager, MiniDispatcher三个服务在ZooKeeper下保存着各自的相关信息,通过ZooKeeperHaServices保证服务的高可用;三个服务的启动过程是通过AkkaRPC + 状态机的设计模式实现的,在各服务对象创建过程中注册生成AkkaServer,在服务启动过程中通过AkkaRPC调用不同状态机函数,最后回调onStart执行实际的启动逻辑,完整的启动逻辑较为复杂,需耐心翻阅;状态机默认状态是:StoppedState.STOPPED,AkkaServer创建逻辑在AkkaRpcService.startServer内,另外,在AkkaRpcService.startServer内通过调用AkkaRpcService.registerAkkaRpcActor创建AkkaRpcActor,AkkaRpcActor为具体接收消息并执行状态机逻辑的入口,接收消息的处理逻辑在AbstractActor.createReceive内;
- 创建并启动
- 调用
3. 调用
Dispatcher.runJob进入JobManager启动流程:- 调用
Dispatcher.createJobManagerRunner创建JobManagerRunnerImpl,JobMaster对象,JobMaster代表了一个运行的JobGraph,在JobMaster::new过程中创建了RpcServer,DefaultScheduler,SchedulerImpl,SlotPoolImpl,ExecutionGraph,CheckpointCoordinator等重要对象,创建ExecutionGraph入口:SchedulerBase.createExecutionGraph; - 调用
Dispatcher.startJobManagerRunner执行整个任务的提交流程:启动JobManager端各服务模块,申请Slot资源启动TaskManager,提交/执行Task等流程;
4. 从调用
JobManagerRunnerImpl.start开始到DefaultScheduler.allocateSlotsAndDeploy结束- 在这段代码调用区间内主要做了一些服务的启动,
Job状态的变更和监听服务的添加,为JobManager添加监控指标;代码较简单,在此不一一说明;
5. 调用
DefaultScheduler.allocateSlots进入资源申请流程: // TODO find slot from existing resource, if don‘t find request resourceManager for a new resource AMRMClientAsyncImpl.CallbackHandlerThread // get Resource that have been allocated and callYarnResourceManager.onContainersAllocatedto process TaskManager AMRMClientAsyncImpl.HeartbeatThread // invokeAMRMClientImpl.allocateperiodically, ResourceManager will be called to allocate Resource YarnResourceManager.requestYarnContainer // put request of allocate Container to member variableAMRMClientImpl.ask6. 调用
DefaultScheduler.waitForAllSlotsAndDeploy进入Task发布流程// TODO
获取到的 container 资源存放在纳贡,以供给后序 slot 分配; start TaskManager and register it to JobManager
[Server] 启动 TaskManager
// TODO
- YarnResourceManager.onContainersAllocated
- org.apache.flink.yarn.YarnTaskExecutorRunner
内存计算
- start command for TaskManager -> TaskExecutorProcessUtils.processSpecFromWorkerResourceSpec
- resource request for TaskManager -> WorkerSpecContainerResourceAdapter.createAndMapContainerResource
参考文档
-
产品线迁移私有云的问题汇总
概述
公司领导在 19 年底确定将所有服务迁移到某云服务,我所在团队负责的两条产品线需在六月前完成迁移;这两条产品线承载着公司 80%数据收集和报表计算&查询服务,指标较多且系统复杂,迁移压力略大;从 20 年初开始制定迁移方案,进行实际的迁移操作,整个迁移在团队 4 个人的全职投入和在 DBA、基础组件同事的协助下最终在 5 月中旬完成迁移。本文目的在于简单记录下自己在迁移过程中所遇到的一些技术问题。
说明
两条产品线主要功能有数据收集,实时数据处理,离线数据处理,指标查询四类,涉及到的需迁移的技术组件如下:
- 数据收集:
Collector(自研,Go 实现); - 实时处理:
Kafka,Flink,Etl-formwork(自研 Pipeline); - 离线处理:
Crontab + Hive + Python2; - 存储服务:
Druid,Hadoop,Cassandra,Mongo,ES,Mysql,Redis; - 其它服务:
Zookeeper,Jetty,Dubbo,Grafana,Prometheus; - 此外还有些相关组件不在本文关注范围内,例如:
Nginx,VIP等;
在整个迁移过程中自己主要负责:实时/离线计算任务的迁移,实时/历史数据同步,指标核对工具的开发,保证迁移后各指标的准确无误;需迁移技术组件包括:
Kafka,Flink,Zookeeper,Dubbo,Crontab + Hive + Python;问题记录
Dubbo 2.5.3 升级到 2.7.6
-
对
Dubbo进行升级操作的原因:新环境中的调用Dubbo服务耗时较长,导致实时数据处理出现淤积的情况,在Github找到一个类似的issue,随后对Dubbo进行了升级操作,问题得以解决; -
Dubbo 2.7.6基本可以向后兼容性2.5.3,只需升级Dubbo依赖版本,添加Curator依赖,然后将用户代码引入的Dubbo类的路径变更为com.apache即可,如:com.alibaba.dubbo.config.ApplicationConfig变更为org.apache.dubbo.config.ReferenceConfig; -
服务升级后发现在运行日志中有如下报错:
ERROR org.apache.dubbo.qos.server.Server - [DUBBO] qos-server can not bind localhost:22222,直接在Dubbo配置中关闭QOS服务即可;
Hive 0.13 升级 1.2.1/3.1.1
您没看错,确实是
Hive 0.13,且Hive SQL提交到一个Hadoop 0.20的集群上~#.#~;这些批脚本对应的是一条产品线的离线指标计算的业务,这些脚本包含:Shell,Python,Hive SQL等脚本,并依赖了一个Mongo库,一个Jetty服务,三个Mysql库,八个User Jar,几十个UDF;本次迁移必须对Hadoop/Hive做升级,且将脚本的业务逻辑梳理清楚;这些批脚本的迁移大概用了 1 个月的时间;Upgrade to 1.2.1
从
0.13升级到1.2.1过程十分顺利,在自己定义的HiveCli初始化脚本中添加一行配置(set hive.support.sql11.reserved.keywords=false;)即可;主要是因为Hive从1.2.0版本开始,根据SQL2011标准增加了大量reserved keyword,通过这个配置可以保证包含reserved keyword的 SQL 可正常执行;参考:- https://issues.apache.org/jira/browse/HIVE-6617
- https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
Upgrade to 3.1.1
最初迁移时是计划合并多个
Hadoop集群到公司公用的Hadoop 3.1.0集群,对应的 Hive 版本也升级到3.1.1,但最终因牵动项目多(Druid,Etl-Framework),升级风险高而放弃;在Hive的0.13版本升级到3.1.1的测试阶段也解决了多个 SQL 迁移问题,在此做下记录。-
hive.support.sql11.reserved.keywords 配置不可用 在
Hive 2.3之后配置set hive.support.sql11.reserved.keywords=false;已经被移除,所以在 SQL 中有用到reserved keyword做标识符时需要放在反引号(``)内,以消除歧义;社区 issue: https://issues.apache.org/jira/browse/HIVE-14872。 -
Union 两张字段类型不一致的表
Hive 3.1.1环境下当union all两个字段类型不一致的列时,会收到如下报错信息:FAILED: SemanticException 17:71 Schema of both sides of union should match: Column user_offset is of type string on first table and type int on second table. Error encountered near token 'charge_device';看起来是Hive3对union all两侧的数据集进行了类型一致性校验;对类型不一致的列进行CAST(user_offset as int)修改后 SQL 可正常执行; -
hive.strict.checks.type.safety 严格类型安全检查,默认是 true,该属性不允许
bigint 和 string 间的比较,bigint 和 double 间的比较;将属性设置为 false,可以解除不允许上述两种不同类型间的比较的限制,在 SQL 的Where条件中经常会出现这种类型不一致的条件比较。 -
SQL 执行耗时增加:
Hive 3.1.1环境下发现个 SQL 执行特别慢,而同样 SQL 在 Hive0.13 都可以很快执行完成;经过进一步测试发现在Hive3下,查询同一张表的不同字段(如下文提供的 SQL),性能差别很大,在单表数据量40W+的测试条件下,查询某个字段要用 2 个多小时,而查询其他字段只需3~5分钟;同样数据集同样的 SQL 以相同并行度在Hive 0.13下执行,查询时长都可保持在3~5分钟;在修改表数据存储格式(STORED AS PARQUET)后查询慢的问题可以解决,通过hive --debug进行远程Debug发现Hive3对数据反序列化阶段变代码变化较大,但没找到问题根源,先留下个问题和数据,以后再结合JMX,Arthas这些工具看个究竟吧,示例:
-- 表结构: CREATE TABLE `tmp_logout`( `user` map<string,string> COMMENT 'user_info', `device` map<string,string> COMMENT 'device_info', `app` map<string,string> COMMENT 'app_info', `event` struct<eventType:string,attribute:map<string,string>,eventDatas:array<struct<key:string,value:string,type:string>>> COMMENT 'event_info') PARTITIONED BY (`job_time` bigint, `timezone` int) STORED AS TEXTFILE; -- sql_1:执行速度快 insert overwrite directory '/user/hadoop/output/tmp_logout' select app['product_id'] as pid from tmp_logout where job_time=20200420120000 and app['product_id'] is not NULL; --sql_2:刚开始执行较快,但随时间增加执行越来越慢,最终执行完需要2H+,GC时间逐渐增加 insert overwrite directory '/user/hadoop/output/logout' select event.attribute['event_time'] as event_time from tmp_logout where job_time=20200420120000 and app['product_id'] is not NULL;- 其他
尝试将执行引擎从
MR切换到Spark上时,也发现了很多 SQL 执行报错的问题,比如:Hive UDAF执行报错;在 Hive 配置set hive.groupby.skewindata=true;的情况下,有些group by的 SQL 的执行报错(经Calcite优化后的执行计划不一样),等等;总之,需调整的的地方还是挺多的。
Kafka Offset 不提交导致的数据重复消费
用
Flink写了个Kafka To Kafka数据拷贝工具,由于迁移前期两个机房之间的网络不太稳定,为防止数据拷贝任务频繁重启,给Flink Job添加了 checkpoint 失败不重启的配置:env.getCheckpointConfig.setFailOnCheckpointingErrors(false),这个配置导致了数据重复消费的问题;现象:
Checkpoint失败持续了 6 个小时之久且没一次成功;查看日志发现每次 checkpoint 时候都会有如下报错信息:java.lang.IllegalStateException: Correlation id for response (204658) does not match request (204657);FlinkKafkaConsumer09的 Offset 提交模式是OffsetCommitMode.ON_CHECKPOINTS;查看Kafka-Manager的Consumer Offset监控,发现一直没变化;重启 Job 发现 6 小时内的数据出现重复消费的问题。解决: 在社区看到一个相同的问题:https://issues.apache.org/jira/browse/KAFKA-4669;后来关闭了测试数据拷贝并将流量较大的几个
Topic切到kafka-mirror-maker.sh上,问题得以暂时解决;当前 BUG 并未根除,当前问题也先遗留下来后序再看看源码吧。JDK7 升级到 JDK8
在升级 JDK 版本后,业务代码调用 ES 接口时报错,相关信息如下:
// 调用 ES API 的用户代码 String value = String.valueOf(hits[0].field(collFields[i]).getValue()); // SearchHitField.java 被调用的方法 <V> V getValue(); // 报错信息:java.lang.ClassCastException: java.lang.Object cannot be cast to [C // 用户代码反编译结果: // String value = String.valueOf((char[]) hits[0].field(collFields[i]).getValue()); // 正确写法 Object obj = hits[0].field(collFields[i]).getValue(); String value = String.valueOf(obj);从上述信息我们可以判断,当前这个报错是因为:在编过程中,用户代码上下文没有足够的信息给到编译器进行泛型类型的推断;贴一个文章作为学习参考:http://lovestblog.cn/blog/2016/04/03/type-inference/?from=groupmessage;
其他问题
-
公司机房有高 IO 需求的服务如:
Druid Historical, Kafka, Cassandra, ES, Mysql, etc.都是用的12块HDD做Raid5;而到云服务是单独的磁盘阵列,能加多块盘,但没办法做Raid5,单块磁盘读写上限限制到80M/s,此外:听说磁盘和主机是分别存放并通过光纤链接到一起的;这使得前期压测花费了不少时间在磁盘性能测试上,在整个迁移过程中也做了几次的磁盘参数调整,或是更换高性能 SSD 的工作; -
Mysql,Redis,Cassandra这些服务是通过建立跨机房集群来完成实时数据迁移的,对跨机房的网络稳定性要求较高,期间由于大量历史数据跨机房拷贝导致了网络堵塞,这影响到了这些跨机房服务的正常运行; -
Druid,Hadoop,ES等服务是通过在云上新装集群,然后通过distcp,elasticdump命令将历史数据跨机房拷贝到云服务上的; -
刚开始时,机房间的通信用是一根 10G 光纤,所有团队服务都走这一根光纤,互相会有影响,后又拉了根 5G 光纤;
-
Kafka集群在负载不高的情况下,上游数据写入出现淤积的情况,运维同事帮忙调整了下网卡参数(ethtool -L eth0 combined 2,ethtool -l eth0)并重启机器后,淤积情况有所缓解; -
Kafka 0.8.1版本问题较多,迁移到了Kafka 0.9集群,Kafka0.8.1遇到的问题有:recovery threads只有一个线程且不能配置;删除Topic会导致Broker的报错日志激增,必须手动清楚ZK上的Delete Topic信息,并重启所有Broker;auto.leader.rebalance.enable=false是默认配置,会导致Broker压力不均衡,需修改为true;
- 数据收集:
-
flink日常问题记录
Intro
在Flink的日常使用过程中总会遇到一些值得记录的问题,有些问题复杂度不高,不必要用单独的篇幅记录,就将这些问题都汇总到当前这篇文内。
issue: Checkpoint Failed
环境:
Flink 1.7.1+Hadoop 3.1.0(新IDC机房)+Kafka 0.9(云机房)背景: 公司决定将现有机房迁移到
某云+新的IDC机房;Hadoop 3.1.0公共大集群,Kafka 0.9部署在团队自己的云主机上;Job描述: 实时ETL,Flink读取Kafka数据经过处理后写入ES或Kafka等存储,State Operator为
FlinkKafkaConsumer,checkpoint state为kafka consumer offset,每个state大小在7~10K之间;异常信息:
2020-01-02 17:18:53,337 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Source: analytics_standarddata_weapp_share-druid -> XXXXXXXXXX (1/1) (c2e77749126a67db62d38bdb166b5696) switched from RUNNING to FAILED. AsynchronousException{java.lang.Exception: Could not materialize checkpoint 60 for operator Source: analytics_standarddata_weapp_share-druid -> XXXXXXXXXX (1/1).} at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointExceptionHandler.tryHandleCheckpointException(StreamTask.java:1153) at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.handleExecutionException(StreamTask.java:947) at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:884) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.Exception: Could not materialize checkpoint 60 for operator Source: analytics_standarddata_weapp_share-druid -> XXXXXXXXXX (1/1). at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.handleExecutionException(StreamTask.java:942) ... 6 more Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Could not flush and close the file system output stream to hdfs:/saas/app/flink/checkpoints/1a3bc71ac57f33961637adf340e9c28f/chk-60/253fc668-9241-41c7-994d-3e72aa7281ef in order to obtain the stream state handle at java.util.concurrent.FutureTask.report(FutureTask.java:122) at java.util.concurrent.FutureTask.get(FutureTask.java:192) at org.apache.flink.util.FutureUtil.runIfNotDoneAndGet(FutureUtil.java:53) at org.apache.flink.streaming.api.operators.OperatorSnapshotFinalizer.<init>(OperatorSnapshotFinalizer.java:53) at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:853) ... 5 more Caused by: java.io.IOException: Could not flush and close the file system output stream to hdfs:/saas/app/flink/checkpoints/1a3bc71ac57f33961637adf340e9c28f/chk-60/253fc668-9241-41c7-994d-3e72aa7281ef in order to obtain the stream state handle at org.apache.flink.runtime.state.filesystem.FsCheckpointStreamFactory$FsCheckpointStateOutputStream.closeAndGetHandle(FsCheckpointStreamFactory.java:326) at org.apache.flink.runtime.state.DefaultOperatorStateBackend$DefaultOperatorStateBackendSnapshotStrategy$1.callInternal(DefaultOperatorStateBackend.java:767) at org.apache.flink.runtime.state.DefaultOperatorStateBackend$DefaultOperatorStateBackendSnapshotStrategy$1.callInternal(DefaultOperatorStateBackend.java:696) at org.apache.flink.runtime.state.AsyncSnapshotCallable.call(AsyncSnapshotCallable.java:76) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at org.apache.flink.util.FutureUtil.runIfNotDoneAndGet(FutureUtil.java:50) ... 7 more ......异常说明: 每隔
10~30min就会出现一次state checkpoint failed.,进而导致Job重启(checkpoint默认策略,可配置),Job Log中发现上述错误信息;异常排查:
- 起初怀疑是机房间的网络不稳定(Kafka和Flink在同一个城市内的不同机房~~),虽然有20G的专线;找运维同事协助测试的网络延迟属正常,延迟都在2~3ms之间(
icmp_seq=105 ttl=58 time=2.25 ms 11:09:05),没有网络波动出现; - 然后怀疑是Hdfs问题,因checkpoint主要做了两个事情:跨机房获取
consumed offset和write state to HDFS; - 重新check错误日志,找到异常在Flink框架内中最早发生位置,即:
FsCheckpointStreamFactory$FsCheckpointStateOutputStream.closeAndGetHandle(...),阅读源码,了解具体操作; FsCheckpointStateOutputStream.closeAndGetHandle(...)操作很简单,就是将state从byte[]写入到HDFS File,中间没有多余的操作;- 计划统计从刚进入
FsCheckpointStateOutputStream.closeAndGetHandle(...)到抛出异常的总耗时,用来定位是否存在写HDFS慢的情况,进而导致整个checkpoint failed; - 修改源码,在方法开始执行/抛出异常时记录
system timestamp,在异常信息上添加这些打点的timestamp信息; - 重新编译源码:
cd flink-runtime/,mvn clean compile,得到编译好的FsCheckpointStreamFactory$FsCheckpointStateOutputStream.class文件; - 用新编译的.class文件替换flink-dist_2.11-1.7.1.jar中的
FsCheckpointStreamFactory$FsCheckpointStateOutputStream.class,操作指南:# step 1:将flink-dist_2.11-1.7.1.jar中的文件解压出来: > jar -xvf flink-dist_2.11-1.7.1.jar org/apache/flink/runtime/state/filesystem/FsCheckpointStreamFactory\$FsCheckpointStateOutputStream.class # step 2:用新的.class覆盖刚解压出来的 > cp -f <new_class_file> org/apache/flink/runtime/state/filesystem/ # step 3:将新的.class文件加入到flink-dist_2.11-1.7.1.jar > jar -uvf flink-dist_2.11-1.7.1.jar org/apache/flink/runtime/state/filesystem/FsCheckpointStreamFactory\$FsCheckpointStateOutputStream.class - 重新提交程序,当出现当前异常时查看错误日志,如下:
Could not flush and close the file system output stream to hdfs:/saas/app/flink/checkpoints/cbf5c27f63a7a4724538f3fd9f2ef551/chk-363/01fc22d3-f24b-40c1-9728-cc50dc2e14d2 in order to obtain the stream state handle, enter timestamp:1578025396026, failed timestamp:1578025433855, duration: 37829;方法总执行时间为37_829ms,远超过checkpoint timeout设置10_000ms;到此,可以初步判定checkpoint异常和写HDFS耗时过长有关,但并不清楚每隔10~30min就出现一次写HDFS慢的原因; - 与熟悉Hadoop同事沟通这个问题,最终发现是因为HDFS周期性的做
Directory Scan耗时太长造成的,HDFS Log: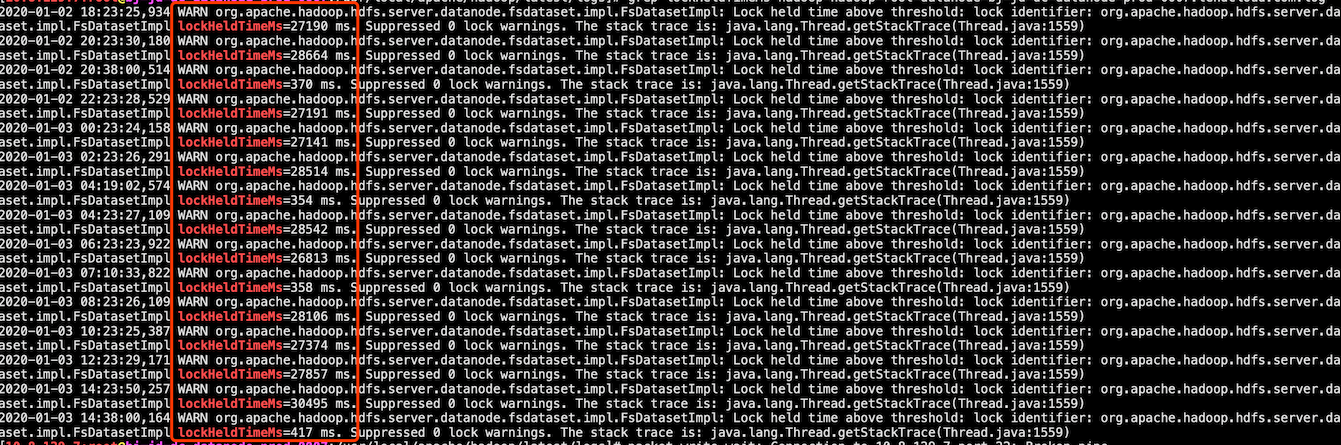
DirectoryScanner属于一个Hadoop版本缺陷,具体可查看jira:https://issues.apache.org/jira/browse/HDFS-14476- 到此,问题已明确,下一步的修复方案也就可以拟定咯,比如:增大hdfs-core.xml中的scan interval配置
dfs.datanode.directoryscan.interval,修改job checkpoint相关配置(setCheckpointTimeout/setFailOnCheckpointingErrors/etc.),然而这些都不治本,最好还是Hadoop打补丁,但又没那么快; - 最后,公共Hadoop集群有
2E个文件,略微有点多惹~~~
- 起初怀疑是机房间的网络不稳定(Kafka和Flink在同一个城市内的不同机房~~),虽然有20G的专线;找运维同事协助测试的网络延迟属正常,延迟都在2~3ms之间(
-
一个简单的Flink Job,一次复杂的问题排查
概括
本文主要是记录一个非常简单的
Flink Job在从Standalone迁移OnYarn时所遇到的一个因内存占用超出限制而引发的Container频繁被Yarn Kill的问题。问题的解决过程主要经历了:Flink监控指标分析,GC日志的排查,TaskManger内存分析,Container的内存计算方法,栈内存的分析等内容;问题描述
起因: 希望将
Flink Standalone上一个简单的Job迁移到Flink On Yarn,迁移前的版本为Flink 1.3.2,迁移目标版本为Flink 1.7.1 + Hadoop 3.1.0;Job描述:
- 有10个
Kafka Topic,每个Topic的Partition数为21; - 有10个
ES Index,每个Index对应一个Topic; - Job消费Topic数据,经过Filter将结果写入对应的Index;
- 任务提交脚本:
flink run -m yarn-cluster -yn 11 -ys 2 -ytm 6g -ynm original-data-filter-prod -d -yq XXX.jar 21 - Job逻辑视图如下:
graph LR A(Source: KafkaSource) --> B(Filter: Operator) B --> C(Sink: Es Index) - 图中
source/filter/sink的并行度一致,以保证Operator Chain - 由于所有Operator都chain在一起,则运行的总Task数量为
10 Topic * 21 parallelism = 210,在考虑到Slot Sharing情况下每个Container内运行的Task数为:10个20,1个10; - 执行计划:
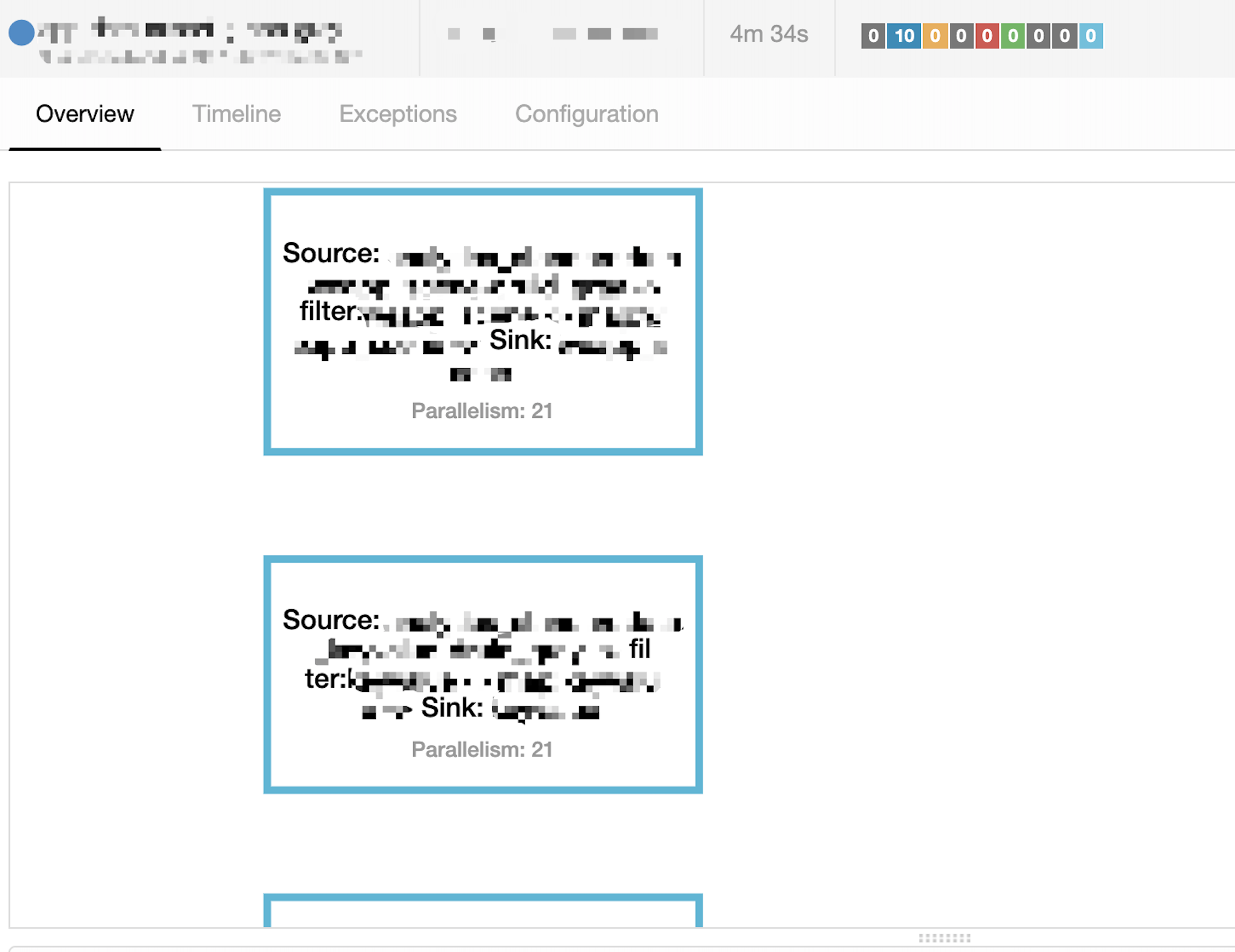
异常描述:
Job正常启动后TaskManager所在的Container每3~5min会被Yarn Kill掉,然后ApplicationMaster会重新向Yarn申请一个新的Container以启动之前被Kill掉的,整个Job会陷入
Kill Container/Apply For New Container/Run Task/ Kill Container...的循环,在Flink和Yarn的日志里都会发现如下错误信息:2019-11-25 20:12:41,138 INFO org.apache.flink.yarn.YarnResourceManager - Closing TaskExecutor connection container_e03_1559725928417_0577_01_001065 because: [2019-11-25 20:12:36.159]Container [pid=97191,containerID=container_e03_1559725928417_0577_01_001065] is running 168853504B beyond the 'PHYSICAL' memory limit. Current usage: 6.2 GB of 6 GB physical memory used; 9.8 GB of 60 GB virtual memory used. Killing container. Dump of the process-tree for container_e03_1559725928417_0577_01_001065 : |- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE |- 97215 97191 97191 97191 (java) 87864 3747 10359721984 1613717 /usr/java/default/bin/java -Xms4425m -Xmx4425m -XX:MaxDirectMemorySize=1719m -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+ParallelRefProcEnabled -XX:ErrorFile=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/hs_err_pid%p.log -Xloggc:/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/gc.log -XX:HeapDumpPath=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -Dlog.file=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner --configDir . |- 97191 97189 97191 97191 (bash) 0 0 118067200 371 /bin/bash -c /usr/java/default/bin/java -Xms4425m -Xmx4425m -XX:MaxDirectMemorySize=1719m -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+ParallelRefProcEnabled -XX:ErrorFile=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/hs_err_pid%p.log -Xloggc:/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/gc.log -XX:HeapDumpPath=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -Dlog.file=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner --configDir . 1> /home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/taskmanager.out 2> /home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/taskmanager.err [2019-11-25 20:12:36.175]Container killed on request. Exit code is 143 [2019-11-25 20:12:38.293]Container exited with a non-zero exit code 143.问题分析
看到上述异常信息,第一直觉是heap或off-heap的Memory占用过大,应该先分析下Container的内存占用情况。
信息:
- Container进程启动使用的Memory配置:
-Xms4425m -Xmx4425m -XX:MaxDirectMemorySize=1719m; - 生产环境中与Memory相关的Flink配置:
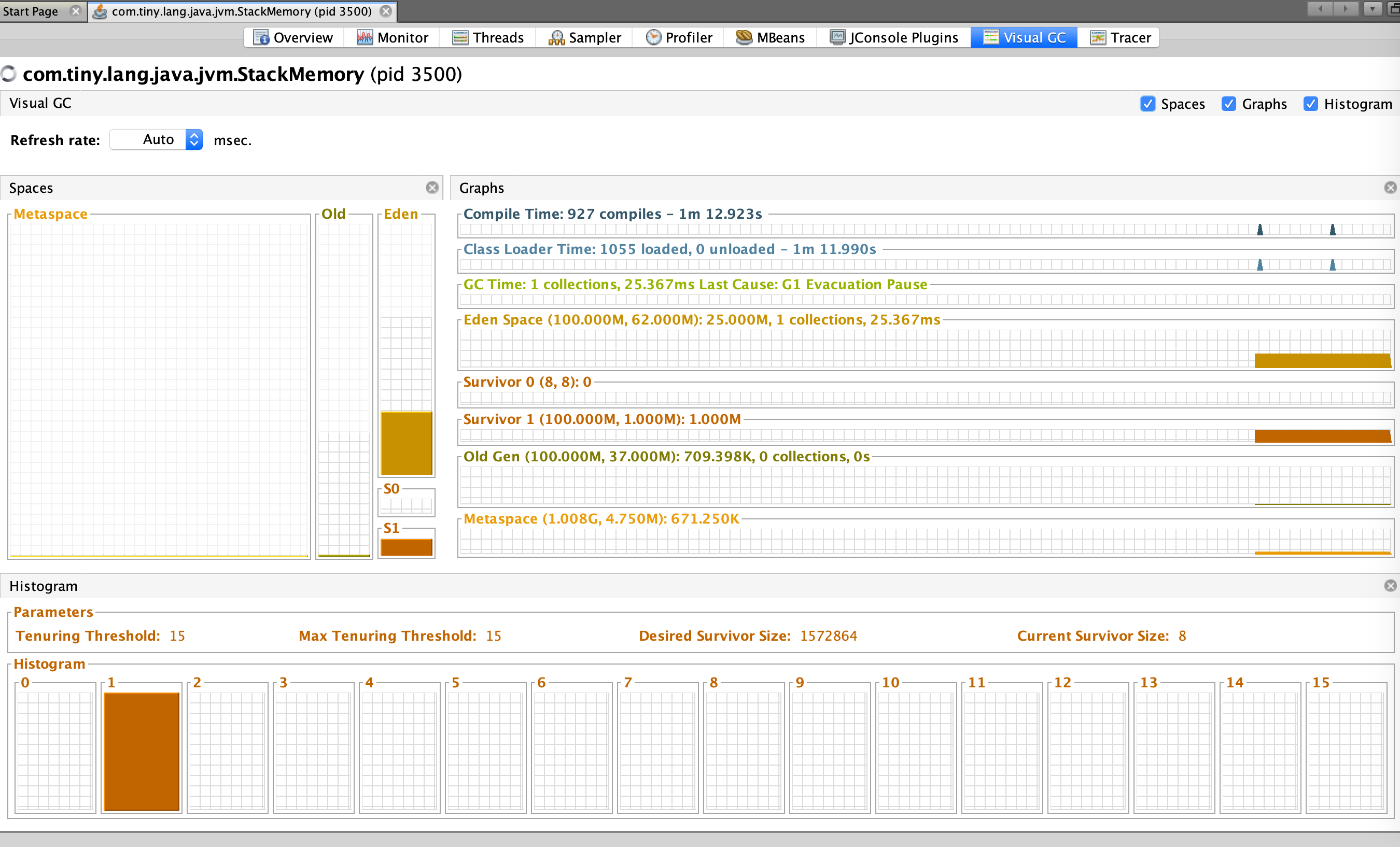
# defined configuration taskmanager.heap.size: 2048m # 默认为2G,当前Job中被覆盖为6G,指定Container Memory(heap+off-heap); taskmanager.memory.preallocate: true # Whether pre-allocated memory of taskManager managed containerized.heap-cutoff-min: 900 # 安全边界,从Container移除的最小 Heap Memory Size containerized.heap-cutoff-ratio: 0.2 # 移除的Heap Memory的比例,用于计算Container进程的heap和max off-heap的大小,max off-heap越大留给Flink之外服务的Memory越多,这些空间一般被用作Container,Socket通信或是一些堆外Cache等; Flink Web Dashboard中heap/off-heap的监控如下图: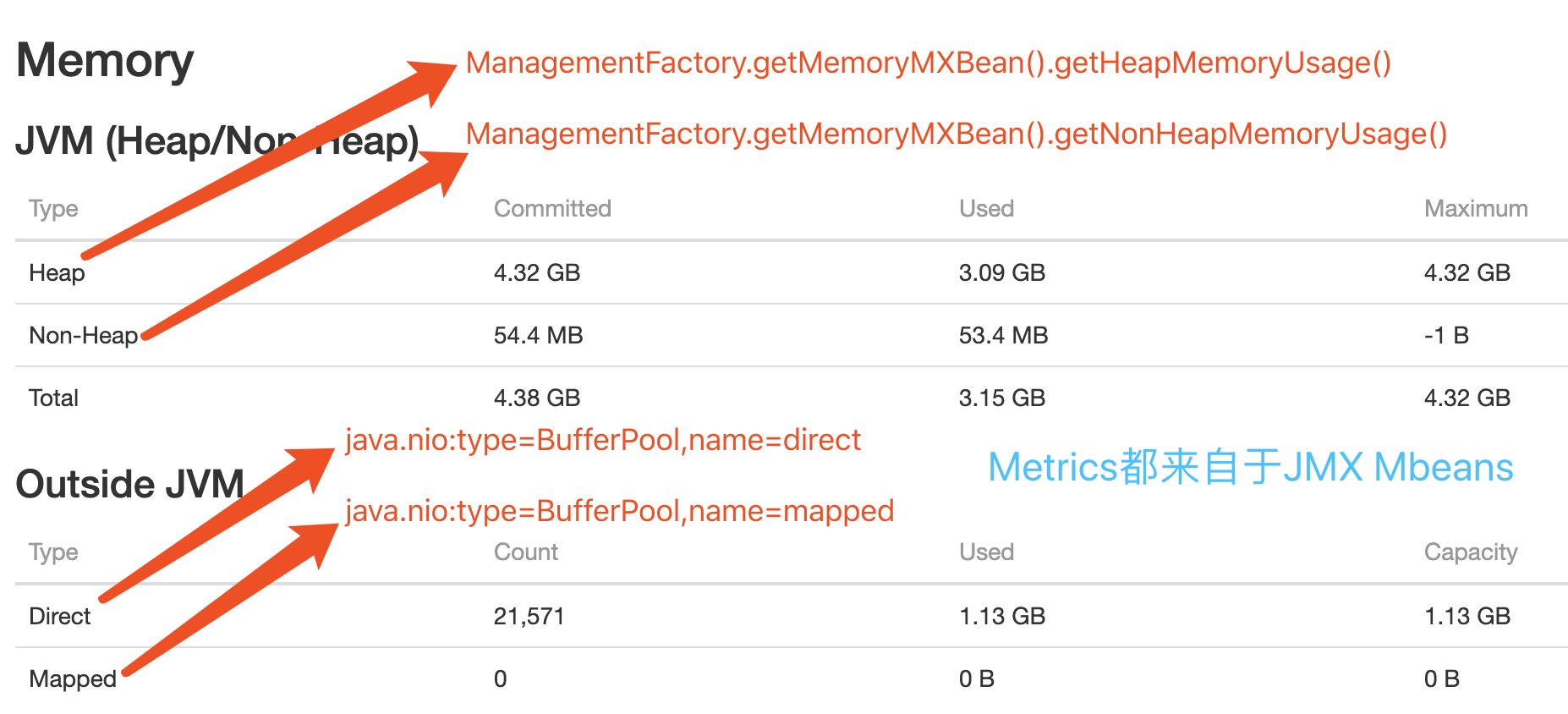
- 被Kill的Container最后一次GC Log:
[Eden: 642.0M(642.0M)->0.0B(676.0M) Survivors: 32.0M->26.0M Heap: 3893.9M(4426.0M)->3245.6M(4426.0M)]
分析: 通过
Flink Log和Web Dashborad查看到上述四项有关Container启动/运行时的信息,发现heap和off-heap都在合理的范围(有足够的空闲Memory),但heap占用的Memory一直在3.8G左右,感觉上这个值属正常,但仍有侥幸心理:先降低heap占用试下。这时做了一次Flink配置修改:taskmanager.memory.preallocate: false,这个配置主要是针对TaskManager Managed Memory的,与之相关的还有taskmanager.memory.off-heap,taskmanager.memory.fraction等,详细说明见:Flink Configuration Doc。修改配置后重启Job,正常运行了几分钟后问题又再次出现,Container被Kill前最后一次GC Log:
[Eden: 192.0M(192.0M)->0.0B(194.0M) Survivors: 28.0M->26.0M Heap: 2629.3M(4426.0M)->250.2M(4426.0M)],从Web Dashboard中观察到的最大heap used是3.7G,off-heap used是1.3G。思考:
heap/off-heap memory在任意时间的实际使用量都在-Xmx4425m -XX:MaxDirectMemorySize=1719m范围内(而且有足够的空闲空间)变化,同时Xmx + MaxDirectMemorySize = 6G,所以任何时间的Memory使用:heap + off-heap < 6G;另一方面:若heap + off-heap > 6G,则应该抛出OOM的异常,所以判定当前问题与Heap/Off-heap的实际占用没有直接关系。接下来有两个疑问:1. Container Memory的计算逻辑是什么,使得计算结果出现大于6G的情况?2. 一个JVM进程包括:Heap, Off-heap, Non-heap, Stack等区域,前三个在Web Dashboard可以看到并且内存总和不大于6G,而Stack内存占用并不能直接观察到,当前问题是否由Stack占用的Memory过大而引起?现在我们不但可以确定当前问题与Heap/Off-heap没有直接的因果关系,而且下一步的分析方向可以明确了。
1. Container Memory的计算逻辑:
- Hadoop NodeManager有一个Monitor线程,它负责监控Container使用的
Physical Memory和Virtual Memory是否超出限制,默认检查周期:3s,代码逻辑可查看:MonitoringThread。 Container Memory的内存量计算有ProcfsBasedProcessTree和CombinedResourceCalculator两种实现,默认情况下使用ProcfsBasedProcessTree。ProcfsBasedProcessTree通过Page数量 * Page大小来计算Physical Memory的使用量,其中Page数量从文件/proc/<pid>/stat解析获得,单Page大小通知执行shell命令getconfg PAGESIZE获取,代码截图如下: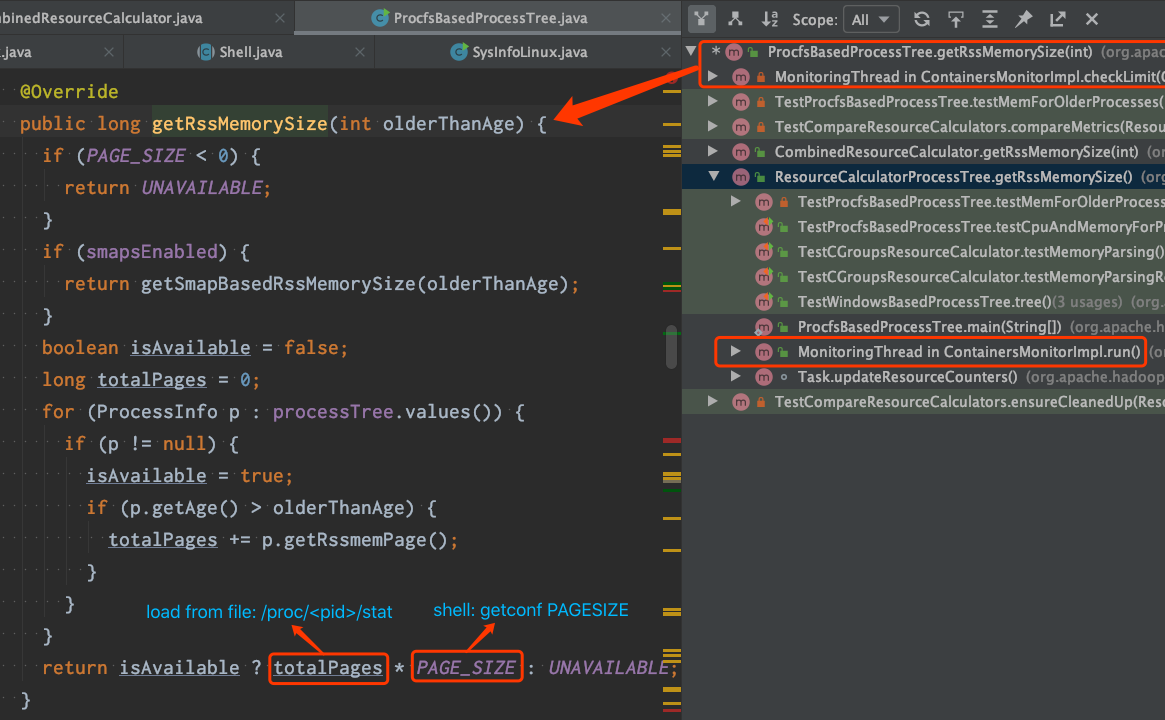
2. Stack Memory的分配区域:
由于JVM功底并不深,初听
Stack Memory具体在哪个区域分配,还真不能准确回答~~。JVM规范定义:Each Java Virtual Machine thread has a private Java Virtual Machine stack, created at the same time as the thread. A Java Virtual Machine stack stores frames (§2.6). A Java Virtual Machine stack is analogous to the stack of a conventional language such as C: it holds local variables and partial results, and plays a part in method invocation and return. Because the Java Virtual Machine stack is never manipulated directly except to push and pop frames, frames may be heap allocated. The memory for a Java Virtual Machine stack does not need to be contiguous.。这段定义并没对Stack Memory的分配做明确定义,只有两句线索:frames may be heap allocated和stack does not need to be contiguous,各JVM产品可对Stack Memory的分配做各自的灵活实现。对自己来说C++暂时是座难翻越的山,也不必要那么兴师动众~~~,直接上测试Code看吧:/** * jvm env: Oracle JDK-8 * jvm conf: * -Xmx200m -Xms200m -Xss5m -XX:MaxDirectMemorySize=10m -XX:NativeMemoryTracking=detail */ public static void main(String[] args) { List<Thread> list = new ArrayList<>(10000); int num = 500; while (num-- > 0) { Thread thread = new Thread(() -> method(0)); thread.start(); list.add(thread); } list.forEach(thread -> { try { thread.join(); } catch (InterruptedException e) { e.printStackTrace(); } }); } private static void method(long i) { int loop = 1024 * 16; if (i < loop) { method(++i); } else { try { System.out.println(i); Thread.sleep(60 * 60 * 1000); } catch (InterruptedException e) { e.printStackTrace(); } } }查看测试DEMO的内存占用,执行Command:
jcmd <pid> VM.native_memory scale=MB结果如下:Native Memory Tracking: Total: reserved=4028MB, committed=2766MB - Java Heap (reserved=100MB, committed=100MB) (mmap: reserved=100MB, committed=100MB) - Class (reserved=1032MB, committed=5MB) (classes #860) ( instance classes #748, array classes #112) (mmap: reserved=1032MB, committed=5MB) ( Metadata: ) ( reserved=8MB, committed=4MB) ( used=1MB) ( free=4MB) ( waste=0MB =0.00%) ( Class space:) ( reserved=1024MB, committed=1MB) ( used=0MB) ( free=0MB) ( waste=0MB =0.00%) - Thread (reserved=2575MB, committed=2575MB) (thread #529) (stack: reserved=2573MB, committed=2573MB) (malloc=2MB #2663) (arena=1MB #1057) - Code (reserved=242MB, committed=7MB) (mmap: reserved=242MB, committed=7MB) - GC (reserved=56MB, committed=56MB) (malloc=21MB #1143) (mmap: reserved=36MB, committed=36MB) - Internal (reserved=3MB, committed=3MB) (malloc=3MB #15173) - Symbol (reserved=1MB, committed=1MB) (malloc=1MB #1352) - Native Memory Tracking (reserved=1MB, committed=1MB) - Shared class space (reserved=17MB, committed=17MB) (mmap: reserved=17MB, committed=17MB)结论: 从
Native Memory Tracking可以看到Thread Stack Memory占用了2573MB,而heap/off-heap的Memory占用非常低;所以,Stack Memory的分配是在heap/off-heap之外的区域(虽然暂时不完全了解Stack Memory的分配细节)。此时,我们可以合理怀疑当前问题是由Stack Memory占用过多引起的。补充一张测试DEMO的Memory监控(非必须),可以简单的关注下Heap/GC情况:
Container的实际线程情况: 从VisualVM的线程监控中可以看到一个Container进程内有
1734个Live Thread和1622个Daemon Thread,对于一个只有2C6G的进程来讲,线程数太多,不仅会影响到Memory使用,也会给GC/线程上下文切换带来更大的压力;在所有活跃线程里有1200+个是es transport client,占总活跃线程的70%+,如下图: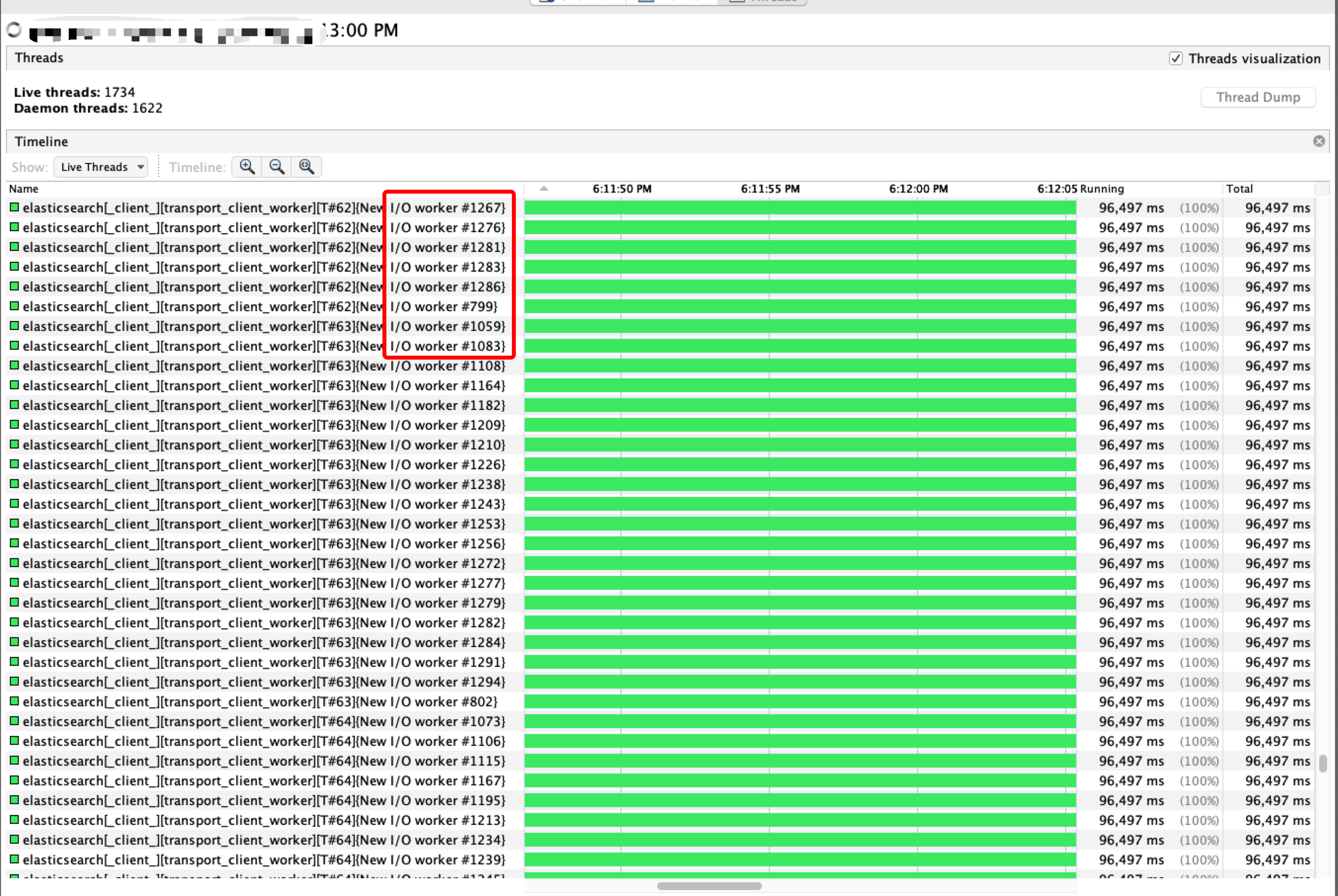
到此,可得出解题方案,即: 减少Container内的
ES Sink实例个数以达到降低es transport client线程数量的目的。将ES Sink的并行度由21调整为2(写数据到ES速度大概为1200+条/s,2个并行度可以满足需求),重启Job后运行正常,当前问题得到完美解决,调整后的执行计划如下图: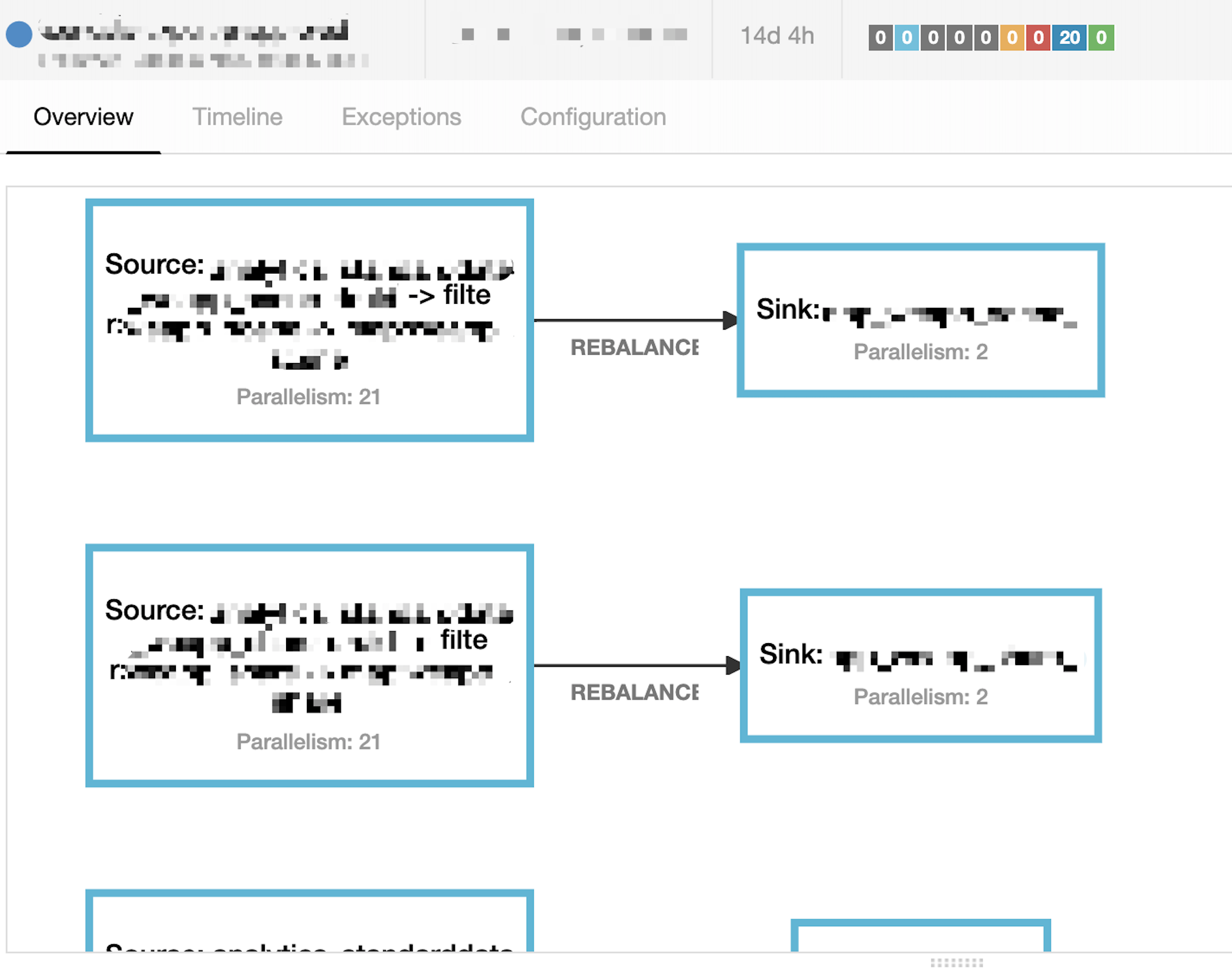
问题遗留&思考
-
内存组成: 除去上述提到的内存使用外还有socket send/receive buffer也占用了一部分空间。
-
快速失败: 当前Yarn或Flink中没有可用的配置来指定
Kill Container或allocate Container的最大次数,以达到在超过某个限制时候,让Job快速失败的目的;Flink中有yarn.maximum-failed-containers配置,当并不适用当前场景;还是需要自己写脚本来完成类似的功能;贴一个反复申请Container的截图:
-
胡思乱想: Flink的Task之间不能共享Operator,Operator也不会有单例的实现,唯一存在的是并行度和Task分配运行策略;若当前问题中一个Container进程内多个Task之间可用共享一个单例的
ES Sink多好~~~,这样就可以少一层物理机间的数据传递。 -
注意小心: Slot Sharing是个很好的特性,可以很大程度提高资源利用率,但也需小心,不要让单个Slot内的Task数量过多。
-
另一种选择: 其实,我们可以通过增大
containerized.heap-cutoff-ratio到0.4或是更高来解决当前问题(预留足够多的Memory给到Stack/Container/Socket使用),但这样势必会减少Heap的大小,考虑到Task内不断增多的Local Cache,所以并未做此调整;另一方面,通过JMX观测到GC的CPU占用超过20%且抖动厉害,只增大MaxDirectMemorySize是解决不了这个GC问题的,而通过减少线程数可以很好减少GCRoot,降低线程切换频率以降低GC压力;
总结
起初对Job的设计思考中是想尽量减少资源占用,最极端的办法就是将数据读取/处理/写出的整个流程放在同一个JVM进程中,这样Operator间的数据传递就可以在进程内部完成而减少网络间的数据传递;由此想到
Chain All Operators Together,这样就必须把source/filter/sink的并行度设置为相同的值;然而,这就让每个Task都持有一个Sink实例,同时因为Slot Sharing特性的存在,每个Container内部会运行多个Task,这就导致单个Container中存在多个Sink实例,特别是Es Sink这种较为重的Operator(内部维护的线程/缓存/状态较多);Es Sink实例对象的增加导致了线程数的成倍增加,所有线程持有的Stack Memory总和也成倍增加,用于运行Job Task的Memory数量进一步减少,另一方面:每个Container所持有的2个CPU资源也很难支撑太多数量的线程高效运行。所以,在了解到上述内容后,首先需要做的事情是减少Container内的线程数(降低
Stack Memory占用,减少频繁的线程上下文切换),减少线程办法就是减少ES Sink的数量(source/filter线程少可忽略不计),从得出了当前的解决方案;最后,将
Es Sink并行度调整为2后问题得到彻底解决,至今Job已平稳运行了半个多月;注: JVM很重要,清晰定位问题很重要;在最初的问题排查过程中,自己总试图从
heap/off-heap占用寻找答案,甚至还将heap/off-heap占用的Memory进行拆分加和以计算是否存在使用过量的情况,耗费了不少精力。Reference
- https://ci.apache.org/projects/flink/flink-docs-master/ops/config.html
- https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-2.html#jvms-2.5.2
- http://blog.jamesdbloom.com/JVMInternals.html#stack
- https://stackoverflow.com/questions/41120129/java-stack-and-heap-memory-management
- https://dzone.com/articles/troubleshoot-outofmemoryerror-unable-to-create-new
- https://stackoverflow.com/questions/36946455/stack-heap-in-jvm
- https://www.baeldung.com/java-stack-heap
- https://www.maolintu.com/2018/02/03/jvm-stack-vs-heap-vs-method-area/
- https://gribblelab.org/CBootCamp/7_Memory_Stack_vs_Heap.html
- https://docs.oracle.com/en/java/javase/13/vm/native-memory-tracking.html
- http://coding-geek.com/jvm-memory-model/
- 有10个