Intro
在Flink的日常使用过程中总会遇到一些值得记录的问题,有些问题复杂度不高,不必要用单独的篇幅记录,就将这些问题都汇总到当前这篇文内。
issue: Checkpoint Failed
环境: Flink 1.7.1 + Hadoop 3.1.0(新IDC机房) + Kafka 0.9(云机房)
背景: 公司决定将现有机房迁移到某云+新的IDC机房;Hadoop 3.1.0公共大集群,Kafka 0.9部署在团队自己的云主机上;
Job描述: 实时ETL,Flink读取Kafka数据经过处理后写入ES或Kafka等存储,State Operator为FlinkKafkaConsumer,checkpoint state为kafka consumer offset,每个state大小在7~10K之间;
异常信息:
2020-01-02 17:18:53,337 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Source: analytics_standarddata_weapp_share-druid -> XXXXXXXXXX (1/1) (c2e77749126a67db62d38bdb166b5696) switched from RUNNING to FAILED.
AsynchronousException{java.lang.Exception: Could not materialize checkpoint 60 for operator Source: analytics_standarddata_weapp_share-druid -> XXXXXXXXXX (1/1).}
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointExceptionHandler.tryHandleCheckpointException(StreamTask.java:1153)
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.handleExecutionException(StreamTask.java:947)
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:884)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.Exception: Could not materialize checkpoint 60 for operator Source: analytics_standarddata_weapp_share-druid -> XXXXXXXXXX (1/1).
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.handleExecutionException(StreamTask.java:942)
... 6 more
Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Could not flush and close the file system output stream to hdfs:/saas/app/flink/checkpoints/1a3bc71ac57f33961637adf340e9c28f/chk-60/253fc668-9241-41c7-994d-3e72aa7281ef in order to obtain the stream state handle
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at org.apache.flink.util.FutureUtil.runIfNotDoneAndGet(FutureUtil.java:53)
at org.apache.flink.streaming.api.operators.OperatorSnapshotFinalizer.<init>(OperatorSnapshotFinalizer.java:53)
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:853)
... 5 more
Caused by: java.io.IOException: Could not flush and close the file system output stream to hdfs:/saas/app/flink/checkpoints/1a3bc71ac57f33961637adf340e9c28f/chk-60/253fc668-9241-41c7-994d-3e72aa7281ef in order to obtain the stream state handle
at org.apache.flink.runtime.state.filesystem.FsCheckpointStreamFactory$FsCheckpointStateOutputStream.closeAndGetHandle(FsCheckpointStreamFactory.java:326)
at org.apache.flink.runtime.state.DefaultOperatorStateBackend$DefaultOperatorStateBackendSnapshotStrategy$1.callInternal(DefaultOperatorStateBackend.java:767)
at org.apache.flink.runtime.state.DefaultOperatorStateBackend$DefaultOperatorStateBackendSnapshotStrategy$1.callInternal(DefaultOperatorStateBackend.java:696)
at org.apache.flink.runtime.state.AsyncSnapshotCallable.call(AsyncSnapshotCallable.java:76)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.flink.util.FutureUtil.runIfNotDoneAndGet(FutureUtil.java:50)
... 7 more
......
异常说明:
每隔10~30min就会出现一次state checkpoint failed.,进而导致Job重启(checkpoint默认策略,可配置),Job Log中发现上述错误信息;
异常排查:
- 起初怀疑是机房间的网络不稳定(Kafka和Flink在同一个城市内的不同机房~~),虽然有20G的专线;找运维同事协助测试的网络延迟属正常,延迟都在2~3ms之间(
icmp_seq=105 ttl=58 time=2.25 ms 11:09:05),没有网络波动出现; - 然后怀疑是Hdfs问题,因checkpoint主要做了两个事情:跨机房获取
consumed offset和write state to HDFS; - 重新check错误日志,找到异常在Flink框架内中最早发生位置,即:
FsCheckpointStreamFactory$FsCheckpointStateOutputStream.closeAndGetHandle(...),阅读源码,了解具体操作; FsCheckpointStateOutputStream.closeAndGetHandle(...)操作很简单,就是将state从byte[]写入到HDFS File,中间没有多余的操作;- 计划统计从刚进入
FsCheckpointStateOutputStream.closeAndGetHandle(...)到抛出异常的总耗时,用来定位是否存在写HDFS慢的情况,进而导致整个checkpoint failed; - 修改源码,在方法开始执行/抛出异常时记录
system timestamp,在异常信息上添加这些打点的timestamp信息; - 重新编译源码:
cd flink-runtime/,mvn clean compile,得到编译好的FsCheckpointStreamFactory$FsCheckpointStateOutputStream.class文件; - 用新编译的.class文件替换flink-dist_2.11-1.7.1.jar中的
FsCheckpointStreamFactory$FsCheckpointStateOutputStream.class,操作指南:# step 1:将flink-dist_2.11-1.7.1.jar中的文件解压出来: > jar -xvf flink-dist_2.11-1.7.1.jar org/apache/flink/runtime/state/filesystem/FsCheckpointStreamFactory\$FsCheckpointStateOutputStream.class # step 2:用新的.class覆盖刚解压出来的 > cp -f <new_class_file> org/apache/flink/runtime/state/filesystem/ # step 3:将新的.class文件加入到flink-dist_2.11-1.7.1.jar > jar -uvf flink-dist_2.11-1.7.1.jar org/apache/flink/runtime/state/filesystem/FsCheckpointStreamFactory\$FsCheckpointStateOutputStream.class - 重新提交程序,当出现当前异常时查看错误日志,如下:
Could not flush and close the file system output stream to hdfs:/saas/app/flink/checkpoints/cbf5c27f63a7a4724538f3fd9f2ef551/chk-363/01fc22d3-f24b-40c1-9728-cc50dc2e14d2 in order to obtain the stream state handle, enter timestamp:1578025396026, failed timestamp:1578025433855, duration: 37829;方法总执行时间为37_829ms,远超过checkpoint timeout设置10_000ms;到此,可以初步判定checkpoint异常和写HDFS耗时过长有关,但并不清楚每隔10~30min就出现一次写HDFS慢的原因; - 与熟悉Hadoop同事沟通这个问题,最终发现是因为HDFS周期性的做
Directory Scan耗时太长造成的,HDFS Log: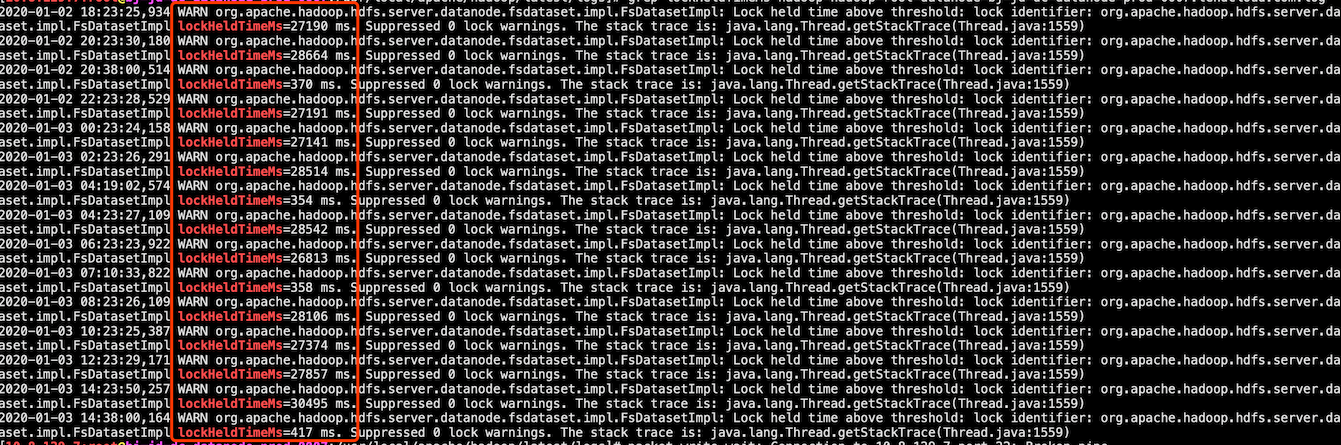
DirectoryScanner属于一个Hadoop版本缺陷,具体可查看jira:https://issues.apache.org/jira/browse/HDFS-14476- 到此,问题已明确,下一步的修复方案也就可以拟定咯,比如:增大hdfs-core.xml中的scan interval配置
dfs.datanode.directoryscan.interval,修改job checkpoint相关配置(setCheckpointTimeout/setFailOnCheckpointingErrors/etc.),然而这些都不治本,最好还是Hadoop打补丁,但又没那么快; - 最后,公共Hadoop集群有
2E个文件,略微有点多惹~~~