概括
本文主要是记录一个非常简单的Flink Job在从Standalone迁移OnYarn时所遇到的一个因内存占用超出限制而引发的Container频繁被Yarn Kill的问题。问题的解决过程主要经历了:Flink监控指标分析,GC日志的排查,TaskManger内存分析,Container的内存计算方法,栈内存的分析等内容;
问题描述
起因: 希望将Flink Standalone上一个简单的Job迁移到Flink On Yarn,迁移前的版本为Flink 1.3.2,迁移目标版本为Flink 1.7.1 + Hadoop 3.1.0;
Job描述:
- 有10个
Kafka Topic,每个Topic的Partition数为21; - 有10个
ES Index,每个Index对应一个Topic; - Job消费Topic数据,经过Filter将结果写入对应的Index;
- 任务提交脚本:
flink run -m yarn-cluster -yn 11 -ys 2 -ytm 6g -ynm original-data-filter-prod -d -yq XXX.jar 21 - Job逻辑视图如下:
graph LR A(Source: KafkaSource) --> B(Filter: Operator) B --> C(Sink: Es Index) - 图中
source/filter/sink的并行度一致,以保证Operator Chain - 由于所有Operator都chain在一起,则运行的总Task数量为
10 Topic * 21 parallelism = 210,在考虑到Slot Sharing情况下每个Container内运行的Task数为:10个20,1个10; - 执行计划:
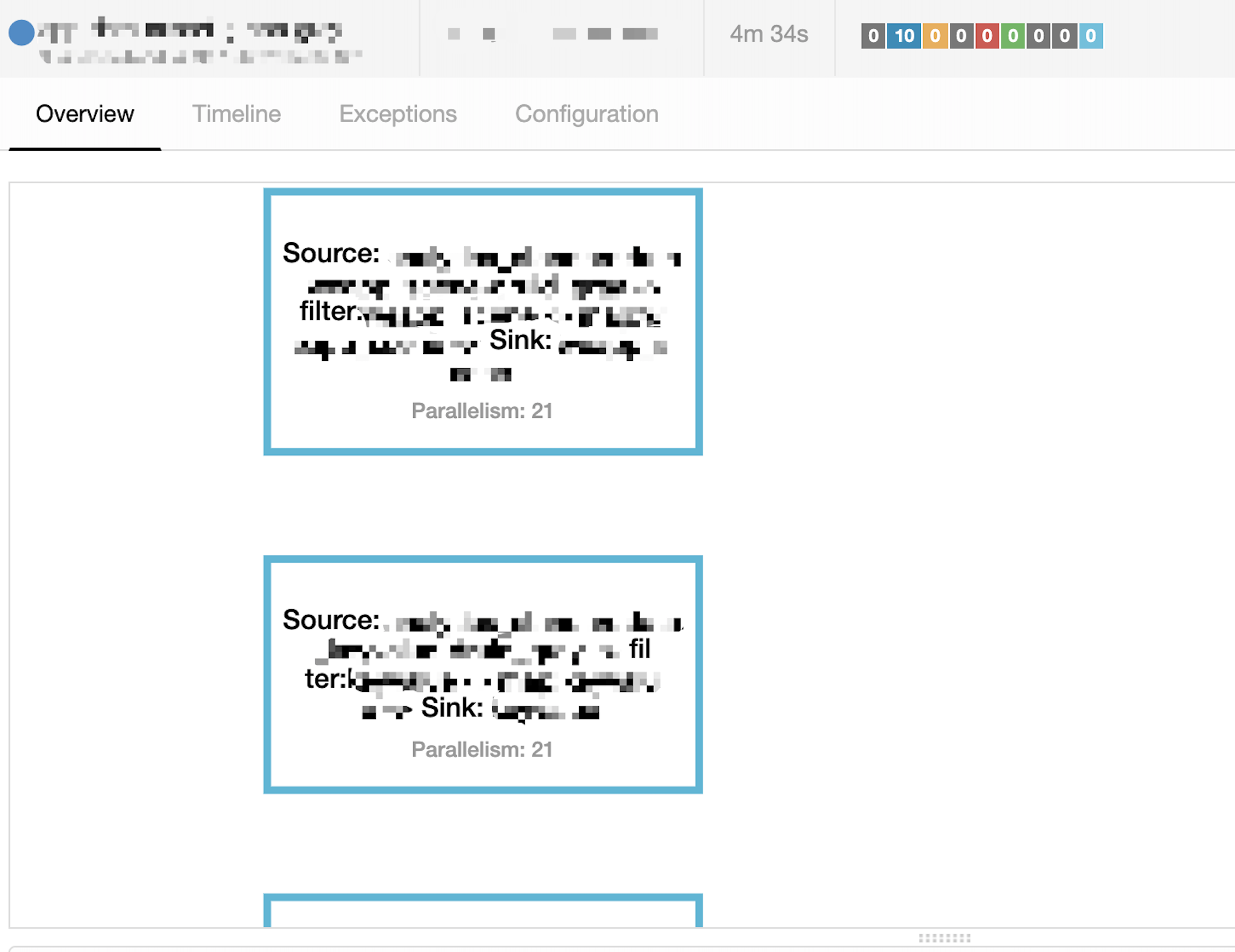
异常描述:
Job正常启动后TaskManager所在的Container每3~5min会被Yarn Kill掉,然后ApplicationMaster会重新向Yarn申请一个新的Container以启动之前被Kill掉的,整个Job会陷入Kill Container/Apply For New Container/Run Task/ Kill Container...的循环,在Flink和Yarn的日志里都会发现如下错误信息:
2019-11-25 20:12:41,138 INFO org.apache.flink.yarn.YarnResourceManager - Closing TaskExecutor connection container_e03_1559725928417_0577_01_001065 because: [2019-11-25 20:12:36.159]Container [pid=97191,containerID=container_e03_1559725928417_0577_01_001065] is running 168853504B beyond the 'PHYSICAL' memory limit. Current usage: 6.2 GB of 6 GB physical memory used; 9.8 GB of 60 GB virtual memory used. Killing container.
Dump of the process-tree for container_e03_1559725928417_0577_01_001065 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 97215 97191 97191 97191 (java) 87864 3747 10359721984 1613717 /usr/java/default/bin/java -Xms4425m -Xmx4425m -XX:MaxDirectMemorySize=1719m -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+ParallelRefProcEnabled -XX:ErrorFile=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/hs_err_pid%p.log -Xloggc:/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/gc.log -XX:HeapDumpPath=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -Dlog.file=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner --configDir .
|- 97191 97189 97191 97191 (bash) 0 0 118067200 371 /bin/bash -c /usr/java/default/bin/java -Xms4425m -Xmx4425m -XX:MaxDirectMemorySize=1719m -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+ParallelRefProcEnabled -XX:ErrorFile=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/hs_err_pid%p.log -Xloggc:/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/gc.log -XX:HeapDumpPath=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -Dlog.file=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner --configDir . 1> /home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/taskmanager.out 2> /home/hadoop/apache/hadoop/latest/logs/userlogs/application_1559725928417_0577/container_e03_1559725928417_0577_01_001065/taskmanager.err
[2019-11-25 20:12:36.175]Container killed on request. Exit code is 143
[2019-11-25 20:12:38.293]Container exited with a non-zero exit code 143.
问题分析
看到上述异常信息,第一直觉是heap或off-heap的Memory占用过大,应该先分析下Container的内存占用情况。
信息:
- Container进程启动使用的Memory配置:
-Xms4425m -Xmx4425m -XX:MaxDirectMemorySize=1719m; - 生产环境中与Memory相关的Flink配置:
# defined configuration taskmanager.heap.size: 2048m # 默认为2G,当前Job中被覆盖为6G,指定Container Memory(heap+off-heap); taskmanager.memory.preallocate: true # Whether pre-allocated memory of taskManager managed containerized.heap-cutoff-min: 900 # 安全边界,从Container移除的最小 Heap Memory Size containerized.heap-cutoff-ratio: 0.2 # 移除的Heap Memory的比例,用于计算Container进程的heap和max off-heap的大小,max off-heap越大留给Flink之外服务的Memory越多,这些空间一般被用作Container,Socket通信或是一些堆外Cache等; Flink Web Dashboard中heap/off-heap的监控如下图: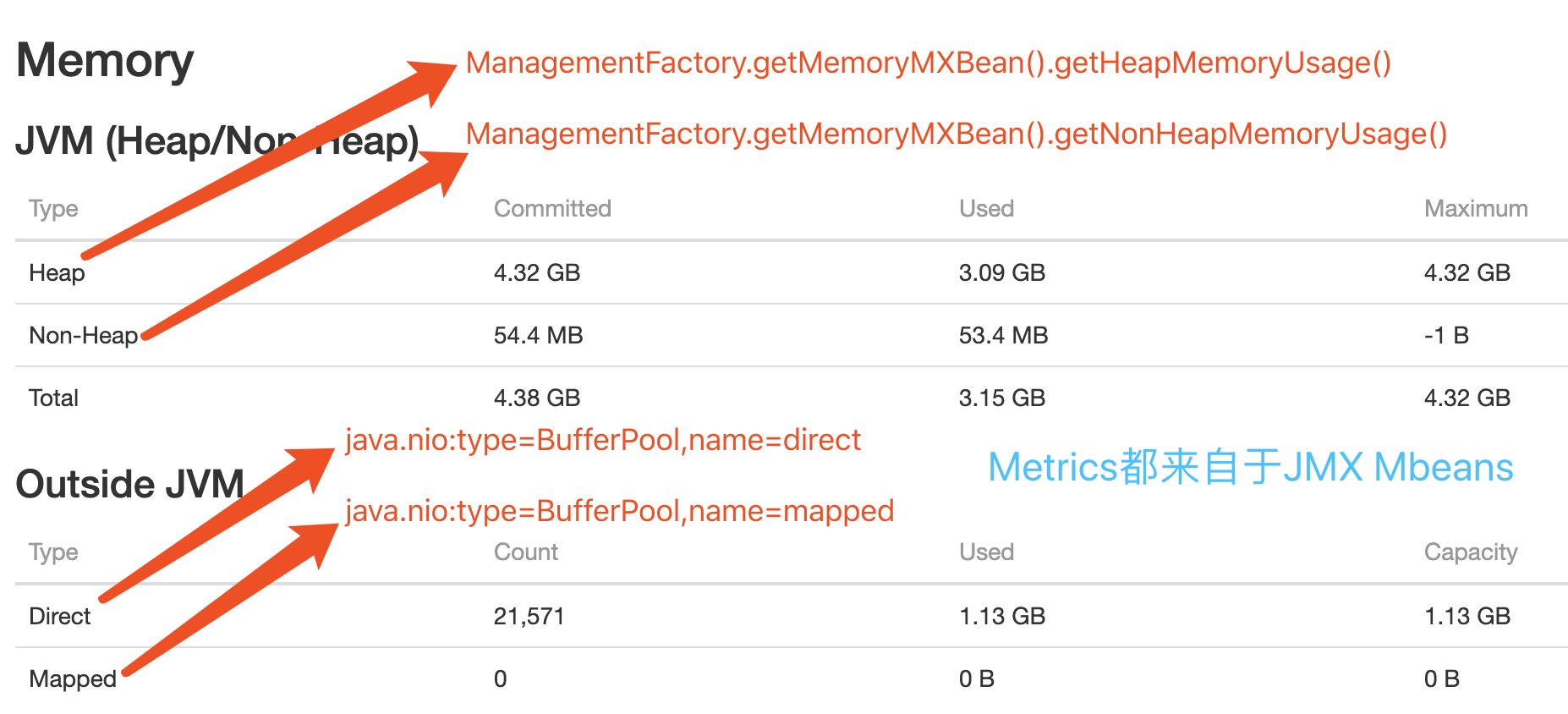
- 被Kill的Container最后一次GC Log:
[Eden: 642.0M(642.0M)->0.0B(676.0M) Survivors: 32.0M->26.0M Heap: 3893.9M(4426.0M)->3245.6M(4426.0M)]
分析:
通过Flink Log和Web Dashborad查看到上述四项有关Container启动/运行时的信息,发现heap和off-heap都在合理的范围(有足够的空闲Memory),但heap占用的Memory一直在3.8G左右,感觉上这个值属正常,但仍有侥幸心理:先降低heap占用试下。这时做了一次Flink配置修改:taskmanager.memory.preallocate: false,这个配置主要是针对TaskManager Managed Memory的,与之相关的还有taskmanager.memory.off-heap, taskmanager.memory.fraction等,详细说明见:Flink Configuration Doc。
修改配置后重启Job,正常运行了几分钟后问题又再次出现,Container被Kill前最后一次GC Log:[Eden: 192.0M(192.0M)->0.0B(194.0M) Survivors: 28.0M->26.0M Heap: 2629.3M(4426.0M)->250.2M(4426.0M)],从Web Dashboard中观察到的最大heap used是3.7G,off-heap used是1.3G。
思考:
heap/off-heap memory在任意时间的实际使用量都在-Xmx4425m -XX:MaxDirectMemorySize=1719m范围内(而且有足够的空闲空间)变化,同时Xmx + MaxDirectMemorySize = 6G,所以任何时间的Memory使用:heap + off-heap < 6G;另一方面:若heap + off-heap > 6G,则应该抛出OOM的异常,所以判定当前问题与Heap/Off-heap的实际占用没有直接关系。接下来有两个疑问:1. Container Memory的计算逻辑是什么,使得计算结果出现大于6G的情况?2. 一个JVM进程包括:Heap, Off-heap, Non-heap, Stack等区域,前三个在Web Dashboard可以看到并且内存总和不大于6G,而Stack内存占用并不能直接观察到,当前问题是否由Stack占用的Memory过大而引起?
现在我们不但可以确定当前问题与Heap/Off-heap没有直接的因果关系,而且下一步的分析方向可以明确了。
1. Container Memory的计算逻辑:
- Hadoop NodeManager有一个Monitor线程,它负责监控Container使用的
Physical Memory和Virtual Memory是否超出限制,默认检查周期:3s,代码逻辑可查看:MonitoringThread。 Container Memory的内存量计算有ProcfsBasedProcessTree和CombinedResourceCalculator两种实现,默认情况下使用ProcfsBasedProcessTree。ProcfsBasedProcessTree通过Page数量 * Page大小来计算Physical Memory的使用量,其中Page数量从文件/proc/<pid>/stat解析获得,单Page大小通知执行shell命令getconfg PAGESIZE获取,代码截图如下: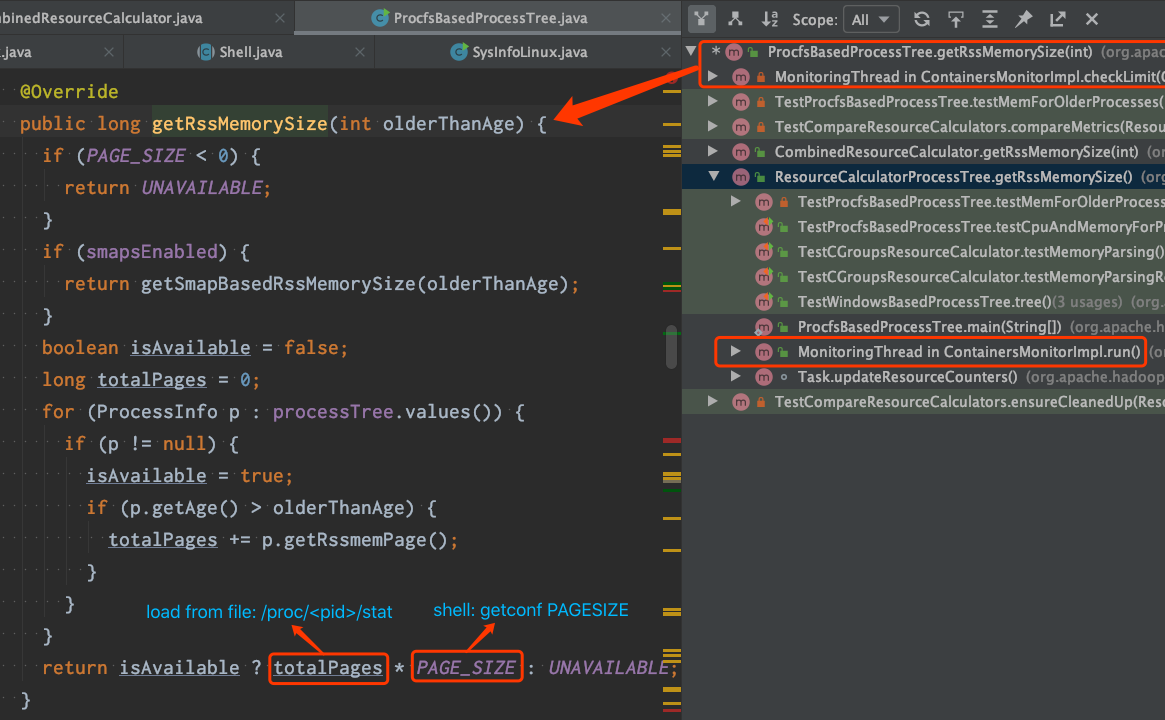
2. Stack Memory的分配区域:
由于JVM功底并不深,初听Stack Memory具体在哪个区域分配,还真不能准确回答~~。JVM规范定义:Each Java Virtual Machine thread has a private Java Virtual Machine stack, created at the same time as the thread. A Java Virtual Machine stack stores frames (§2.6). A Java Virtual Machine stack is analogous to the stack of a conventional language such as C: it holds local variables and partial results, and plays a part in method invocation and return. Because the Java Virtual Machine stack is never manipulated directly except to push and pop frames, frames may be heap allocated. The memory for a Java Virtual Machine stack does not need to be contiguous.。这段定义并没对Stack Memory的分配做明确定义,只有两句线索:frames may be heap allocated和stack does not need to be contiguous,各JVM产品可对Stack Memory的分配做各自的灵活实现。对自己来说C++暂时是座难翻越的山,也不必要那么兴师动众~~~,直接上测试Code看吧:
/**
* jvm env: Oracle JDK-8
* jvm conf:
* -Xmx200m -Xms200m -Xss5m -XX:MaxDirectMemorySize=10m -XX:NativeMemoryTracking=detail
*/
public static void main(String[] args) {
List<Thread> list = new ArrayList<>(10000);
int num = 500;
while (num-- > 0) {
Thread thread = new Thread(() -> method(0));
thread.start();
list.add(thread);
}
list.forEach(thread -> {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
private static void method(long i) {
int loop = 1024 * 16;
if (i < loop) {
method(++i);
} else {
try {
System.out.println(i);
Thread.sleep(60 * 60 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
查看测试DEMO的内存占用,执行Command:jcmd <pid> VM.native_memory scale=MB结果如下:
Native Memory Tracking:
Total: reserved=4028MB, committed=2766MB
- Java Heap (reserved=100MB, committed=100MB)
(mmap: reserved=100MB, committed=100MB)
- Class (reserved=1032MB, committed=5MB)
(classes #860)
( instance classes #748, array classes #112)
(mmap: reserved=1032MB, committed=5MB)
( Metadata: )
( reserved=8MB, committed=4MB)
( used=1MB)
( free=4MB)
( waste=0MB =0.00%)
( Class space:)
( reserved=1024MB, committed=1MB)
( used=0MB)
( free=0MB)
( waste=0MB =0.00%)
- Thread (reserved=2575MB, committed=2575MB)
(thread #529)
(stack: reserved=2573MB, committed=2573MB)
(malloc=2MB #2663)
(arena=1MB #1057)
- Code (reserved=242MB, committed=7MB)
(mmap: reserved=242MB, committed=7MB)
- GC (reserved=56MB, committed=56MB)
(malloc=21MB #1143)
(mmap: reserved=36MB, committed=36MB)
- Internal (reserved=3MB, committed=3MB)
(malloc=3MB #15173)
- Symbol (reserved=1MB, committed=1MB)
(malloc=1MB #1352)
- Native Memory Tracking (reserved=1MB, committed=1MB)
- Shared class space (reserved=17MB, committed=17MB)
(mmap: reserved=17MB, committed=17MB)
结论: 从Native Memory Tracking可以看到Thread Stack Memory占用了2573MB,而heap/off-heap的Memory占用非常低;所以,Stack Memory的分配是在heap/off-heap之外的区域(虽然暂时不完全了解Stack Memory的分配细节)。此时,我们可以合理怀疑当前问题是由Stack Memory占用过多引起的。
补充一张测试DEMO的Memory监控(非必须),可以简单的关注下Heap/GC情况:
Container的实际线程情况:
从VisualVM的线程监控中可以看到一个Container进程内有1734个Live Thread和1622个Daemon Thread,对于一个只有2C6G的进程来讲,线程数太多,不仅会影响到Memory使用,也会给GC/线程上下文切换带来更大的压力;在所有活跃线程里有1200+个是es transport client,占总活跃线程的70%+,如下图:
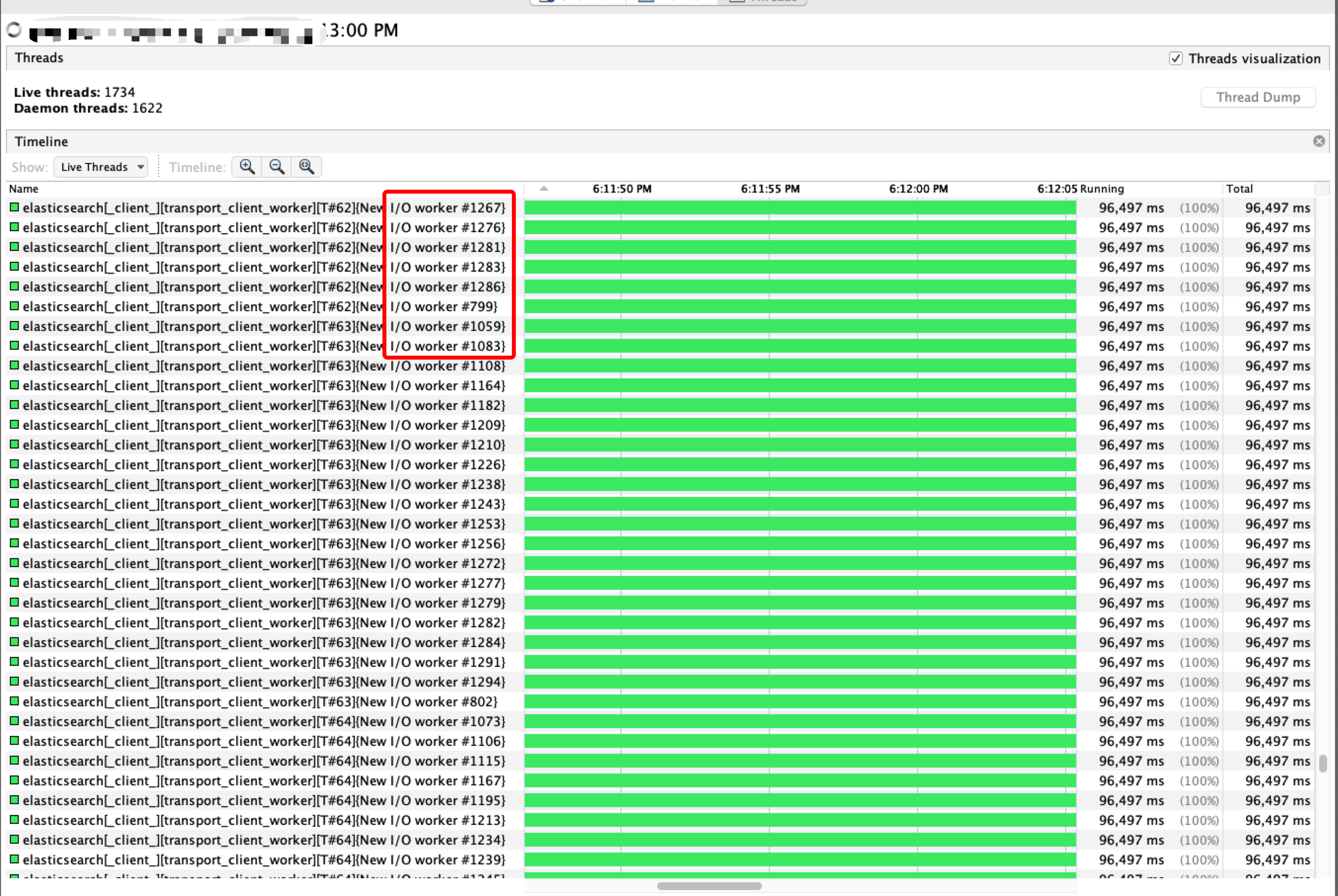
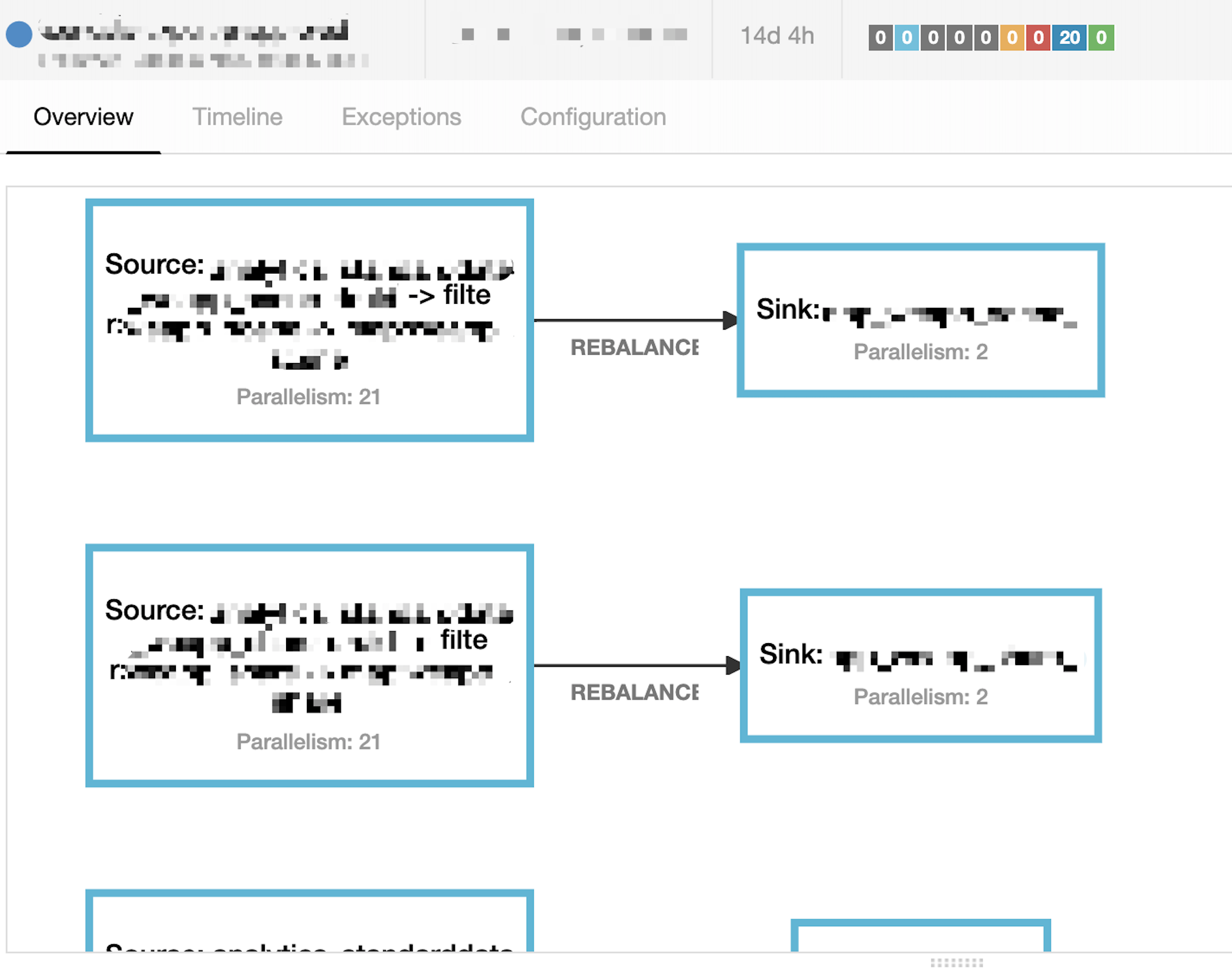
到此,可得出解题方案,即: 减少Container内的ES Sink实例个数以达到降低es transport client线程数量的目的。将ES Sink的并行度由21调整为2(写数据到ES速度大概为1200+条/s,2个并行度可以满足需求),重启Job后运行正常,当前问题得到完美解决,调整后的执行计划如下图:
问题遗留&思考
-
内存组成: 除去上述提到的内存使用外还有socket send/receive buffer也占用了一部分空间。
-
快速失败: 当前Yarn或Flink中没有可用的配置来指定
Kill Container或allocate Container的最大次数,以达到在超过某个限制时候,让Job快速失败的目的;Flink中有yarn.maximum-failed-containers配置,当并不适用当前场景;还是需要自己写脚本来完成类似的功能;贴一个反复申请Container的截图:
-
胡思乱想: Flink的Task之间不能共享Operator,Operator也不会有单例的实现,唯一存在的是并行度和Task分配运行策略;若当前问题中一个Container进程内多个Task之间可用共享一个单例的
ES Sink多好~~~,这样就可以少一层物理机间的数据传递。 -
注意小心: Slot Sharing是个很好的特性,可以很大程度提高资源利用率,但也需小心,不要让单个Slot内的Task数量过多。
-
另一种选择: 其实,我们可以通过增大
containerized.heap-cutoff-ratio到0.4或是更高来解决当前问题(预留足够多的Memory给到Stack/Container/Socket使用),但这样势必会减少Heap的大小,考虑到Task内不断增多的Local Cache,所以并未做此调整;另一方面,通过JMX观测到GC的CPU占用超过20%且抖动厉害,只增大MaxDirectMemorySize是解决不了这个GC问题的,而通过减少线程数可以很好减少GCRoot,降低线程切换频率以降低GC压力;
总结
起初对Job的设计思考中是想尽量减少资源占用,最极端的办法就是将数据读取/处理/写出的整个流程放在同一个JVM进程中,这样Operator间的数据传递就可以在进程内部完成而减少网络间的数据传递;由此想到Chain All Operators Together,这样就必须把source/filter/sink的并行度设置为相同的值;然而,这就让每个Task都持有一个Sink实例,同时因为Slot Sharing特性的存在,每个Container内部会运行多个Task,这就导致单个Container中存在多个Sink实例,特别是Es Sink这种较为重的Operator(内部维护的线程/缓存/状态较多);Es Sink实例对象的增加导致了线程数的成倍增加,所有线程持有的Stack Memory总和也成倍增加,用于运行Job Task的Memory数量进一步减少,另一方面:每个Container所持有的2个CPU资源也很难支撑太多数量的线程高效运行。
所以,在了解到上述内容后,首先需要做的事情是减少Container内的线程数(降低Stack Memory占用,减少频繁的线程上下文切换),减少线程办法就是减少ES Sink的数量(source/filter线程少可忽略不计),从得出了当前的解决方案;
最后,将Es Sink并行度调整为2后问题得到彻底解决,至今Job已平稳运行了半个多月;
注: JVM很重要,清晰定位问题很重要;在最初的问题排查过程中,自己总试图从heap/off-heap占用寻找答案,甚至还将heap/off-heap占用的Memory进行拆分加和以计算是否存在使用过量的情况,耗费了不少精力。
Reference
- https://ci.apache.org/projects/flink/flink-docs-master/ops/config.html
- https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-2.html#jvms-2.5.2
- http://blog.jamesdbloom.com/JVMInternals.html#stack
- https://stackoverflow.com/questions/41120129/java-stack-and-heap-memory-management
- https://dzone.com/articles/troubleshoot-outofmemoryerror-unable-to-create-new
- https://stackoverflow.com/questions/36946455/stack-heap-in-jvm
- https://www.baeldung.com/java-stack-heap
- https://www.maolintu.com/2018/02/03/jvm-stack-vs-heap-vs-method-area/
- https://gribblelab.org/CBootCamp/7_Memory_Stack_vs_Heap.html
- https://docs.oracle.com/en/java/javase/13/vm/native-memory-tracking.html
- http://coding-geek.com/jvm-memory-model/