前言
Flink是由公司前辈引入,最初版本是Flink 1.1.5,后升级到Flink 1.3.2一直以来Flink Job都是跑在Standalone集群上的,为规避Standalone集群中Job相互影响的问题(Standalone无法做资源隔离),前辈们又新做了Flink集群,将互相影响的Job拆分到不同集群中,这时团队内部有多个Flink Standalone集群,虽然解决了部分Job互相影响的问题,但有些服务是和Kafka,Druid部署在同一台物理机器的(不同进程),又出现过几次不同服务互相影响的情况;这些Flink Standalone集群维护/升级起来也挺麻烦的,同时新Job越来越多,生活苦不堪言~.~;兄弟们从2018年初就喊着OnYarn,结果由于人力、机器、业务迭代等各种问题一拖再拖;到2018年底终于开始了这项工作,虽然只1个人力投入,经历2-3个月的时间团队的streaming Job已经稳定运行在OnYarn模式下,本文就重点记录下这段时所遇到的一些重点问题,当前生产运行版本是Flink 1.7.1 + Hadoop 3.1.0
问题汇总
Flink与Hadoop版本兼容性问题
由于官方没有依赖Hadoop 3.1.0的Flink下载包,所以这步需要自行编译Flink源码,可参考官方Doc:https://ci.apache.org/projects/flink/flink-docs-release-1.7/flinkDev/building.html;建议用公司内部环境(Jenkins, JDK, etc.)并结合官方Doc来完成打包。
简单列下我司打包的Jenkins配置:
Branches to build: refs/tags/release-1.7.1
Repository URL: git@gitlab.company.com:git/flink.git
Build - Goals and options: clean install -DskipTests -Dfast -Dhadoop.version=3.1.0
Post Steps - Execute shell: cd flink-dist/target/flink-1.7.1-bin
tar -czvf flink-1.7.1-hadoop31-scala_2.11.tar.gz flink-1.7.1/
报错:
使用./bin/flink run -m yarn-cluster的方式提交Job时出现如下报错:
client端:
------------------------------------------------------------
The program finished with the following exception:
java.lang.RuntimeException: Error deploying the YARN cluster
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.createCluster(FlinkYarnSessionCli.java:556)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.createCluster(FlinkYarnSessionCli.java:72)
at org.apache.flink.client.CliFrontend.createClient(CliFrontend.java:962)
at org.apache.flink.client.CliFrontend.run(CliFrontend.java:243)
at org.apache.flink.client.CliFrontend.parseParameters(CliFrontend.java:1086)
at org.apache.flink.client.CliFrontend$2.call(CliFrontend.java:1133)
at org.apache.flink.client.CliFrontend$2.call(CliFrontend.java:1130)
at org.apache.flink.runtime.security.HadoopSecurityContext$1.run(HadoopSecurityContext.java:43)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1682)
at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:40)
at org.apache.flink.client.CliFrontend.main(CliFrontend.java:1130)
Caused by: java.lang.RuntimeException: Couldn`t deploy Yarn cluster
at org.apache.flink.yarn.AbstractYarnClusterDescriptor.deploy(AbstractYarnClusterDescriptor.java:443)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.createCluster(FlinkYarnSessionCli.java:554)
... 12 more
Caused by: org.apache.flink.yarn.AbstractYarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.
server端:
Uncaught error from thread [flink-akka.remote.default-remote-dispatcher-5] shutting down JVM since 'akka.jvm-exit-on-fatal-error' is enabled for ActorSystem[flink]
java.lang.VerifyError: (class: org/jboss/netty/channel/socket/nio/NioWorkerPool, method: newWorker signature: (Ljava/util/concurrent/Executor;)Lorg/jboss/netty/channel/socket/nio/AbstractNioWorker;) Wrong return type in function
at akka.remote.transport.netty.NettyTransport.<init>(NettyTransport.scala:295)
at akka.remote.transport.netty.NettyTransport.<init>(NettyTransport.scala:251)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
原因:
Flink 1.3.2依赖的Netty3的版本较低,与Hadoop 3.1.0不兼容导致的报错;不兼容的Netty版本为:Netty-3.4.0.Final 和Netty-3.10.6.Final;曾尝试通过修改NioWorkerPool的源文件并编译新的class文件以解决这个问题,但以失败告终;
解决:
升级Flink版本;经测试:Flink 1.6, 1.7 + Hadoop 3.1.0编译出的包是可以正常提交给Hadoop 3.1.0集群的;
结论:
Flink 1.3.2与Hadoop 3.1.0存在兼容性问题,若需提交Flink Job到Hadoop 3.1.0及以上,最好使用Flink 1.6+
Flink-Avro序列化与AllowNull
Flink类型系统和序列化方式可关注官方doc:
https://ci.apache.org/projects/flink/flink-docs-master/dev/types_serialization.html
Flink默认支持PoJoSerializer,AvroSerializer,KryoSerializer三种序列化,官方推荐使用Flink自己实现的PojoSerializer序列化(在遇到无法用PoJoSerializer转化的时默认用KryoSerializer替代,具体可关注GenericTypeInfo),Kryo性能较Avro好些,但无供跨语言的解决方案且序列化结果的自解释性较Avro差;经过功能性能等多方面的调研,计划Task间数据传递用Kryo,提高数据序列化性能,状态的checkpoint,savepoint用Avro,让状态有更好的兼容&可迁移性;此功能从Flink 1.7+开始支持具体关注doc:
https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/stream/state/custom_serialization.html
OK,接下来说遇到的在Avro下的对象序列化异常,本次bug和上边的内容无关~,~. 这个报错只是因为Flink-Avro不支持null的序列化;
报错:
开启Avro序列化(enableForceAvro()),Task间通过网络传递数据对象时,若对象内部有field为null,数据无法正常序列化抛出如下异常:
java.lang.RuntimeException: in com.app.flink.model.Line in string null of string in field switchKey of com.app.flink.model.Line
at org.apache.flink.streaming.runtime.io.RecordWriterOutput.pushToRecordWriter(RecordWriterOutput.java:104)
at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:83)
at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:41)
... more
Caused by: java.lang.NullPointerException: in com.app.flink.model.Line in string null of string in field switchKey of com.app.flink.model.Line
at org.apache.avro.reflect.ReflectDatumWriter.write(ReflectDatumWriter.java:145)
at org.apache.avro.generic.GenericDatumWriter.write(GenericDatumWriter.java:58)
at org.apache.flink.api.java.typeutils.runtime.AvroSerializer.serialize(AvroSerializer.java:135)
... 18 more
Caused by: java.lang.NullPointerException
at org.apache.avro.specific.SpecificDatumWriter.writeString(SpecificDatumWriter.java:65)
at org.apache.avro.generic.GenericDatumWriter.write(GenericDatumWriter.java:76)
at org.apache.avro.reflect.ReflectDatumWriter.write(ReflectDatumWriter.java:143)
at org.apache.avro.generic.GenericDatumWriter.writeField(GenericDatumWriter.java:114)
at org.apache.avro.reflect.ReflectDatumWriter.writeField(ReflectDatumWriter.java:175)
at org.apache.avro.generic.GenericDatumWriter.writeRecord(GenericDatumWriter.java:104)
at org.apache.avro.generic.GenericDatumWriter.write(GenericDatumWriter.java:66)
at org.apache.avro.reflect.ReflectDatumWriter.write(ReflectDatumWriter.java:143)
原因:
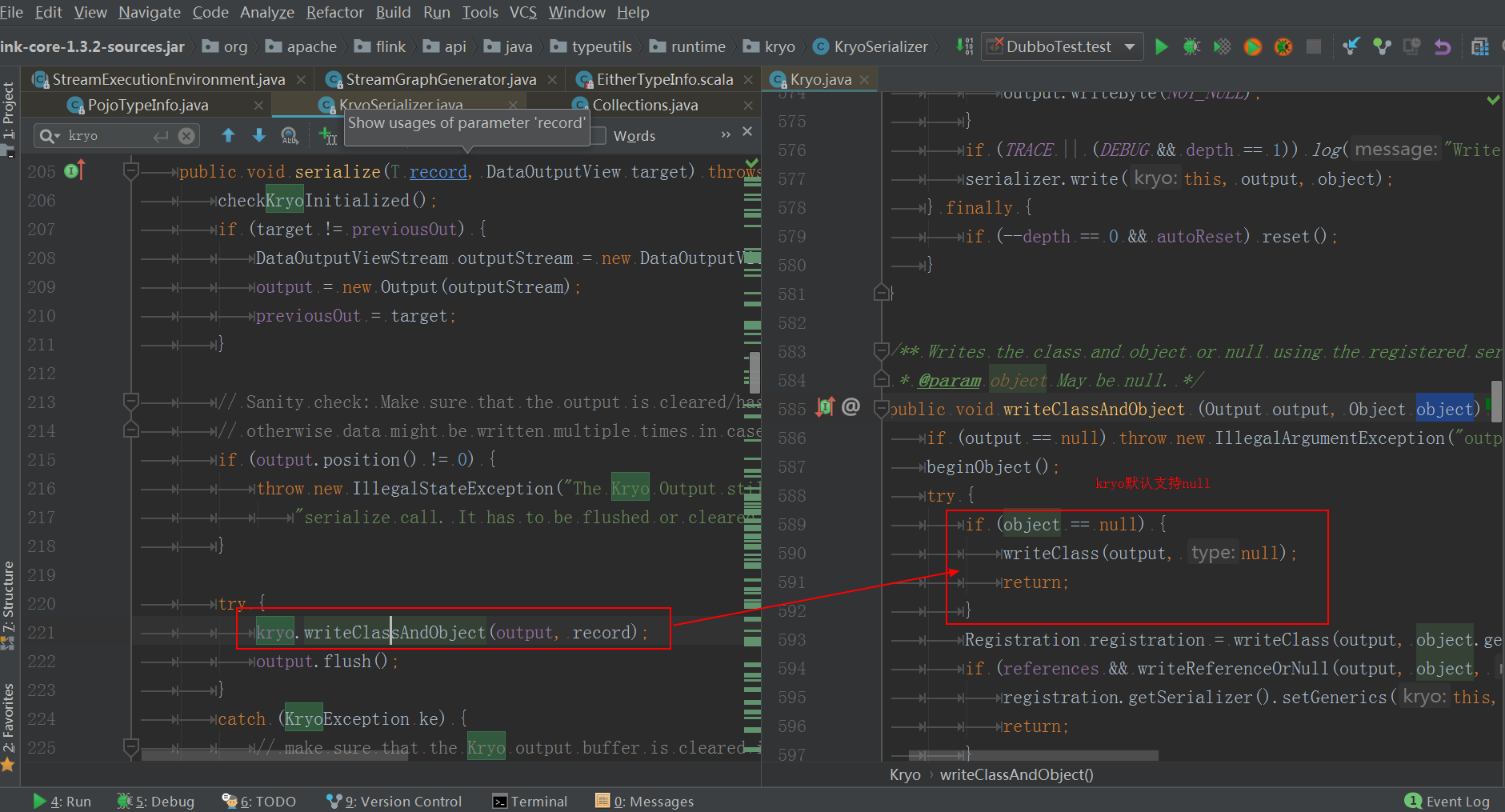
Flink在初始化Avro Serializer时使用org.apache.avro.reflect.ReflectData构造DatumReader和DatumWriter,ReflectData本身不支持null的序列化(Avro有提供ReflectData的扩展类org.apache.avro.reflect.AllowNull来支持null的序列化,但Flink并未使用),从而导致null field的序列化异常;而Kryo默认支持null field,程序可正常运行;Flink 1.3.2下代码截图如下:
Avro:
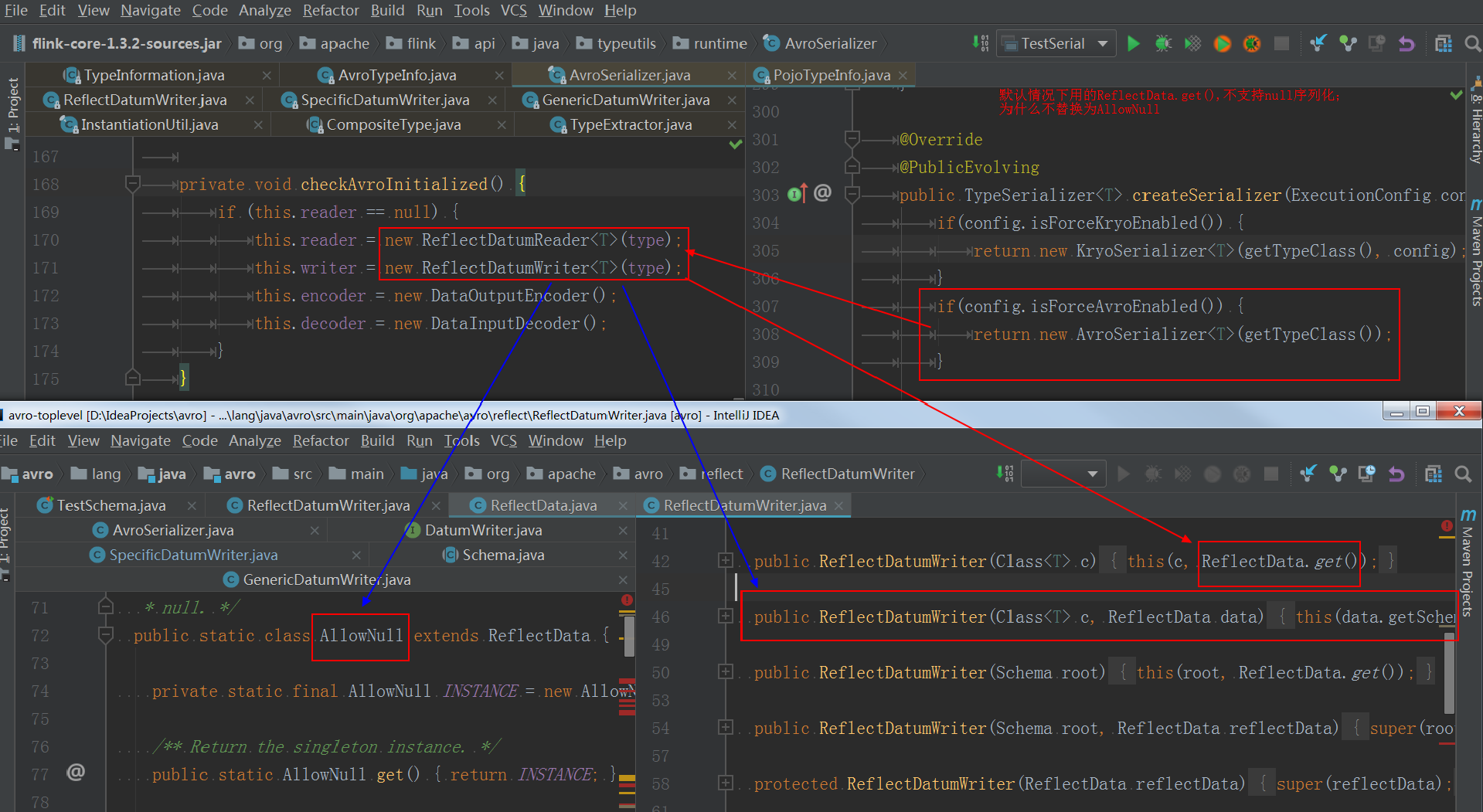
Kryo:
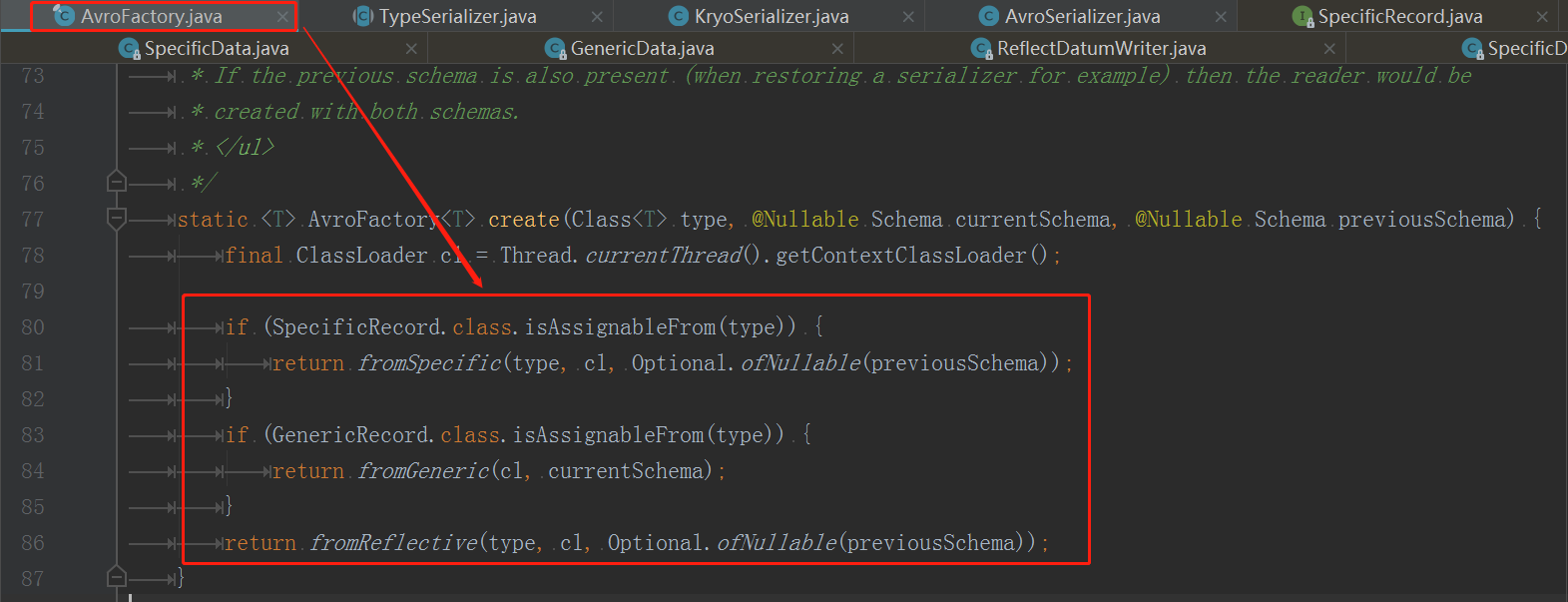
Flink 1.7后对集成Avro的代码变更较大,但依旧会出现当前Bug,代码逻辑入口:
解决:
- 给需要序列化的
field值赋默认值; - 改用
Kryo(enableForceKryo())序列化; - 去除
enableForceXXX()尝试下默认的PoJoSerializer;
ClassLoader导致Failover Failed
本问题在Kafka0.8 + Flink 1.7(cannot guarantee End-to-End exactly once)环境下造成了数据丢失的问题;
报错:
异常一:kafka异常(导致了Job重启)
Caused by: java.lang.Exception: Could not complete snapshot 69 for operator wep
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.snapshotState(AbstractStreamOperator.java:422)
at org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.checkpointStreamOperator(StreamTask.java:1113)
at org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.executeCheckpointing(StreamTask.java:1055)
at org.apache.flink.streaming.runtime.tasks.StreamTask.checkpointState(StreamTask.java:729)
at org.apache.flink.streaming.runtime.tasks.StreamTask.performCheckpoint(StreamTask.java:641)
at org.apache.flink.streaming.runtime.tasks.StreamTask.triggerCheckpointOnBarrier(StreamTask.java:586)
... 8 more
Caused by: java.lang.Exception: Failed to send data to Kafka: This server is not the leader for that topic-partition.
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase.checkErroneous(FlinkKafkaProducerBase.java:375)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase.snapshotState(FlinkKafkaProducerBase.java:363)
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.trySnapshotFunctionState(StreamingFunctionUtils.java:118)
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.snapshotFunctionState(StreamingFunctionUtils.java:99)
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.snapshotState(AbstractUdfStreamOperator.java:90)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.snapshotState(AbstractStreamOperator.java:395)
... 13 more
异常二:Job重启,Dubbo异常
com.alibaba.dubbo.rpc.RpcException: Rpc cluster invoker for interface com.etl.commons.api.GenericService on consumer xxx.xx.xx.xx use dubbo version flink is now destroyed! Can not invoke any more.
at com.alibaba.dubbo.rpc.cluster.support.AbstractClusterInvoker.checkWheatherDestoried(AbstractClusterInvoker.java:233)
at com.alibaba.dubbo.rpc.cluster.support.AbstractClusterInvoker.invoke(AbstractClusterInvoker.java:215)
at com.alibaba.dubbo.rpc.cluster.support.wrapper.MockClusterInvoker.invoke(MockClusterInvoker.java:72)
at com.alibaba.dubbo.rpc.proxy.InvokerInvocationHandler.invoke(InvokerInvocationHandler.java:52)
at com.alibaba.dubbo.common.bytecode.proxy0.queryBaseDimension(proxy0.java)
过程:
Kafka抖动或异常导致Flink sink data to Kafka时丢失Topic Leader(出现异常一),进而导致Flink Job重启;
Flink Job重启正常,Job状态是running,但flink operator中的Dubbo未初始化导致无法提供服务(在Flink Job重启过程中由于DubboService.java中代码不规范而导致Dubbo服务未初始化,Dubbo服务不可用);
Flink Source开始消费数据,当需调用含有DubboService的Operator处理数据时抛异常(出现异常二),数据无法正常处理并下发到下一个ChainOperator;
上游数据不断被消费,但无法正常处理并下发,这就照成的Source端丢数的现象;
原因:
在Standalone模式下Flink Job的失败自动重启Dubbo服务可以正常初始化的,但在OnYarn模式下初始化Dubbo服务会不可用;
Flink Standalone下失败重启过程中,DubboService会先卸载再重新加载,Dubbo服务正常初始化;
OnYarn下失败重启的过程中类DubboService不会被JVM卸载,同时代码书写不规范,导致内存驻留了已被closed的DubboService;
调用已经closed的Dubbo服务则数据无法正常处理并抛异常;
问题代码:
private static DubboService dubboService;
public static void init() {
if (dubboService == null) {
Dubbo.init();
logger.info("Dubbo initialized.");
} else {
logger.info("Dubbo already existed.");
}
}
// 未对dubboService做置空处理
public static void destroy() {
dubboService.destroy();
}
解决:
在destory方法中清除所有static的共享变量,使得job重启时候可以正常重新初始化Dubbo服务,如下代码:
修改代码:
public static void destroy() {
dubboService.destroy();
// 置空
dubboService = null;
}
补充:
OnYarn的Flink Job重启时候是不会释放Container并重新申请的,自动重启前后的JobId保持不变;
Standalone模式下,User code的是在TaskManager环境中加载启动的用的ClassLoader是:org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoader;
OnYarn模式下(bin/flink run -m yarn-cluster),User Code和Flink Framework一并提交到Container中,User Code加载用的ClassLoader是:sun.misc.Launcher$AppClassLoader;
由于ClassLoader不同,导致User Code卸载时机不同,也就导致在OnYarn模式下Restart Job,DubboService初始化异常;
可参考Flink Docs:https://ci.apache.org/projects/flink/flink-docs-release-1.7/monitoring/debugging_classloading.html
注: coding时候尽量用RichFunction 的open()/close()方法初始化对象,尽可能用(单例)对象持有各种资源,减少使用static(生命周期不可控),及时对static修饰对象手动置空;
taskmanager.network.numberOfBuffers配置
解决该问题需要对Flink的Task数据交换&内存管理有深刻的理解,可参考文章: https://cwiki.apache.org/confluence/display/FLINK/Data+exchange+between+tasks
环境:
Job的运行Topology图:
graph LR
A(Task-Front `parallelism:30`) -->|shuffle| D(Task-End `parallelism:90`)
Task-Front负责从Kafka读取数据、清洗、校验、格式化,其并行度为30;
Task-End负责数据的解析&处理,并发送到不同的Kafka Topic;
Task-Front并行度为30,Task-End并行度为90;
Task-Front通过网络IO将数据传递给Task-End;
Job压测环境:
Flink 1.3.2的Standalone模式;
2个JobManager高可用;
8个TaskManager(一台物理机一个TaskManager),主要配置如下:
taskmanager.numberOfTaskSlots: 13
taskmanager.network.numberOfBuffers: 10240
taskmanager.memory.segment-size: 32768 # 32K
taskmanager.memory.size: 15g
问题:
在Standalone下由于taskmanager.network.numberOfBuffers配置数量过小导致data exchange buffer不够用,消费Kafka数据的速度减缓并出现大幅度的抖动,严重情况下导致FlinkKafkaConsumer停止消费数据,从JMX监控看到如下现象:
:
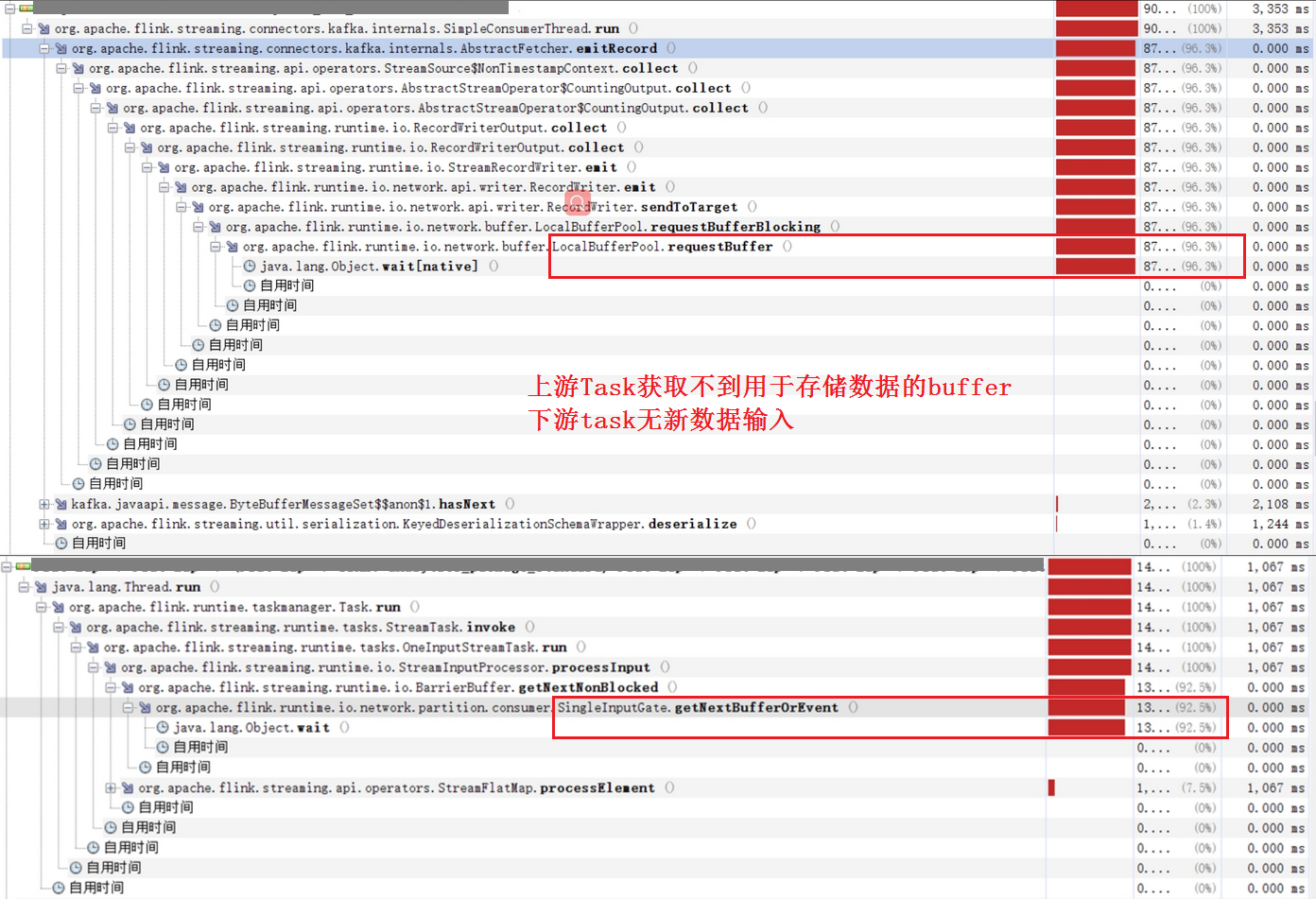
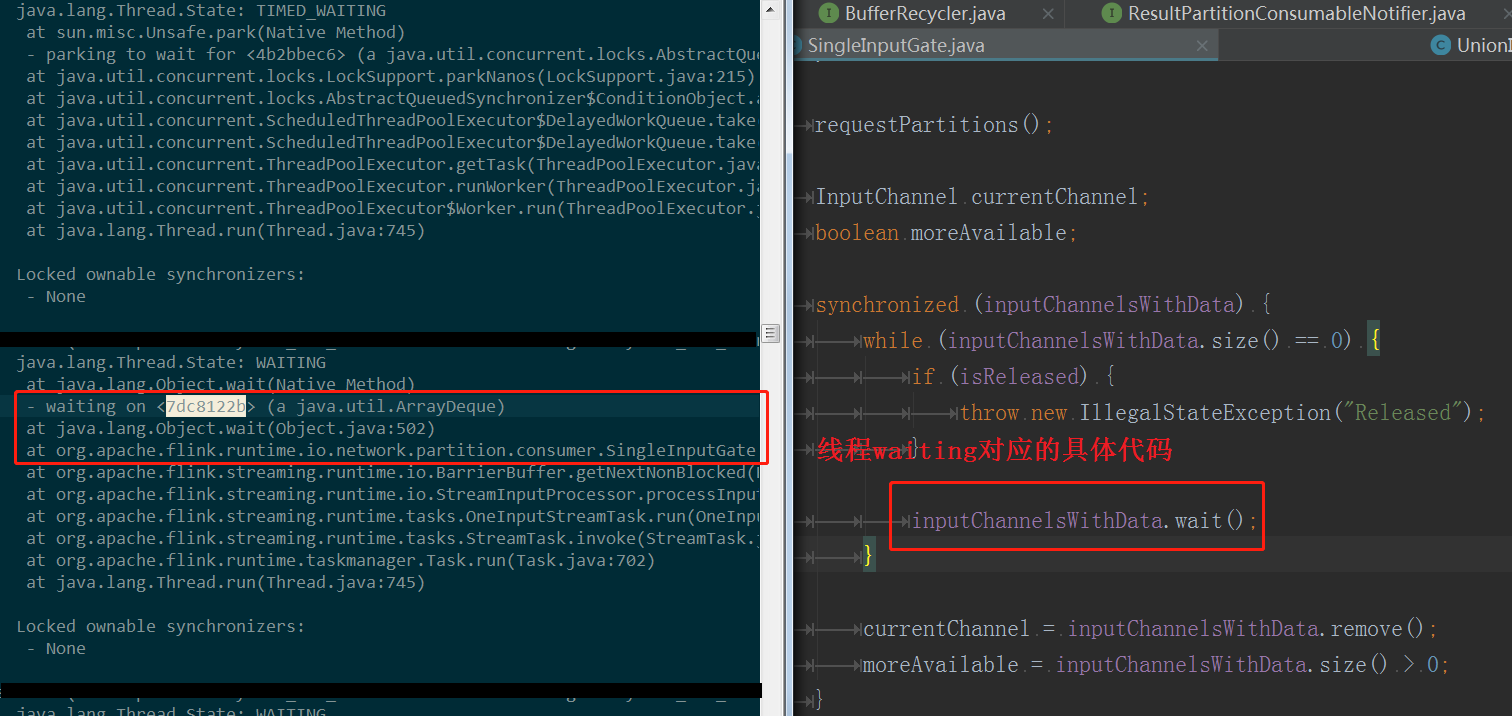
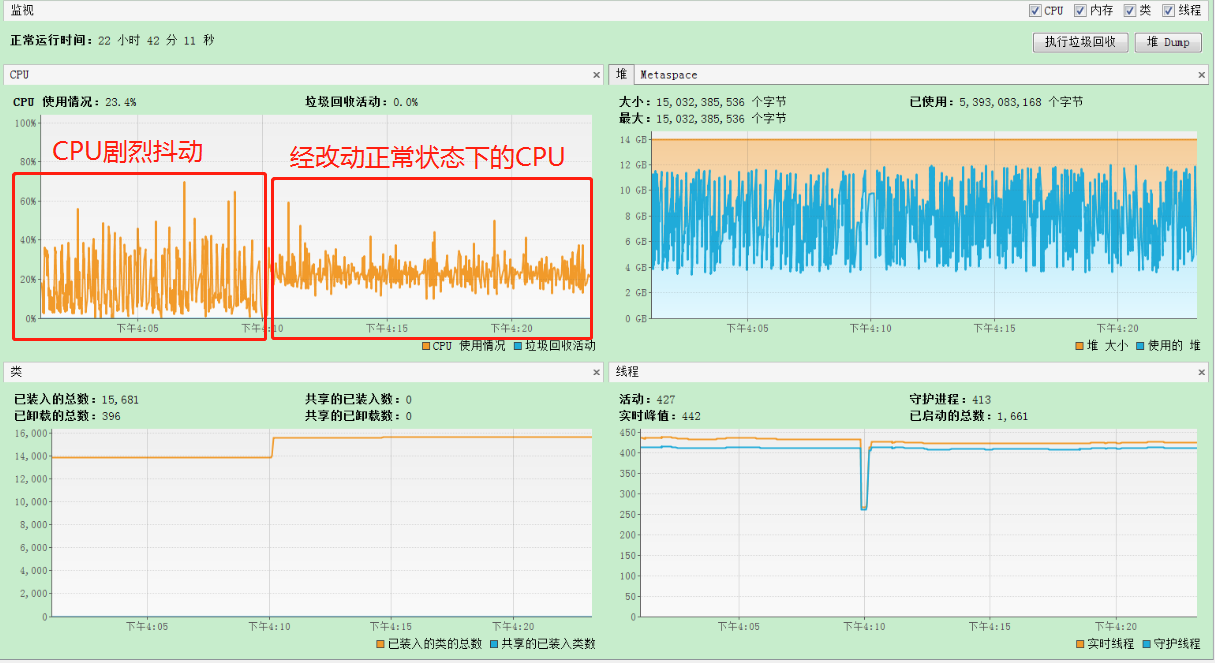
分析:
从JMX监控看,主要是因为Buffer原因导致的线程wait,cpu抖动;
共8台机器,每台机器上有13个Slot,根据Job是30 + 90的并行度来看,每台机器上同时存在多个Task-Front和Task-End;
Task-Front需将处理好的数据存储到ResultPartition;
Task-End需将接收到的数据存储到InputGate以备后续处理;
Task-End将处理好的数据直接发送给Kafka Topic,所以不需要ResultPartition;
一个Task-Front需将自己处理的数据shuffle到90个Task-End;
通过Flink Buffer分配原理可知,需要30*90个ResultPartition,90*30个InputGate;
若平均分则每个ResultPartition/InputGate可分配到的Buffer数量是:
(10240 * 8) / (30*90 + 90 * 30) ≈ 15个(每个32k);
在8w+/s, 5~10k/条的数据量下的15个Buffer会在很短时间被填满,造成Buffer紧缺,Task-Front无法尽快将数据shuffle到下游,Task-End无法获取足够的数据来处理;
解决:
增大taskmanager.network.numberOfBuffers数量,最好保证每个ResultPartition/InputGate分配到90+(压测预估值,不保证效果最佳)的Buffer数量;
补充:
在OnYarn下几乎不会遇到该为题,了解该问题有助于理解Flink内存管理&数据传递;
Flink 1.5之后Buffer默认用堆外内存,并deprecated了taskmanager.network.numberOfBuffers,用taskmanager.network.memory.max与taskmanager.network.memory.min代替;
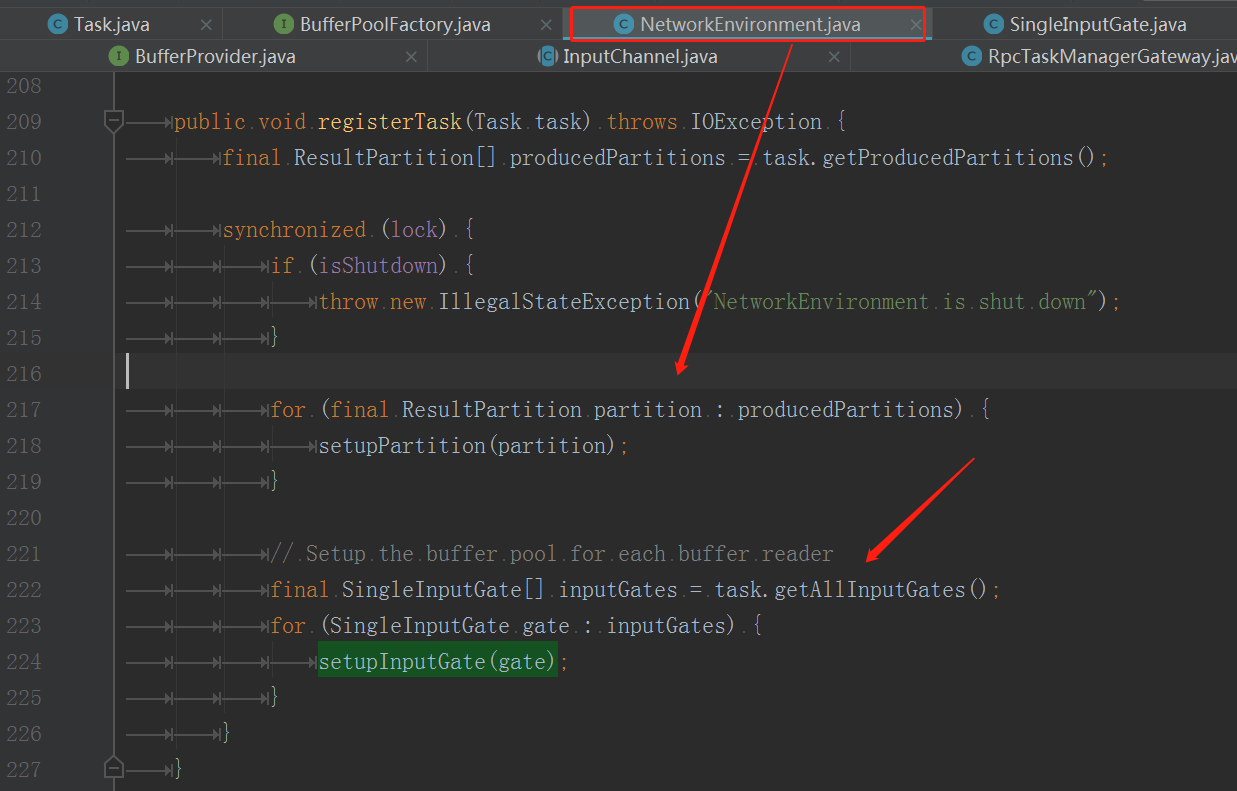
关于Buffer分配&动态调整等逻辑可关注以下几个类:TaskManagerRunner / Task / NetworkEnvironment / LocalBufferPool / InputGate / ResultPartition / MemorySegment,在此不做源码解读,最后贴两个截图:

OnYarn下log的打印
Standalone与OnYarn下的日志配置和输出路径有较大的区别,Standalone下直接在maven的resources目录下配置log4j2.xml/log4j.properties即可完成日志配置,但在OnYarn下 需要通过修改${flink.dir}/conf/log4j.properties的配置来定义日志输出,这些配置在container.sh启动TaskManager/JobManager时被加载以初始化log4j,配置如下:
# Log all infos in the given file
log4j.appender.file=org.apache.log4j.DailyRollingFileAppender
# ${log.file} input by luanch_container.sh
log4j.appender.file.file=${log.file}
log4j.appender.file.append=false
log4j.appender.file.encoding=UTF-8
log4j.appender.file.DatePattern='.'yyyy-MM-dd
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
${flink.dir}/conf下不同log配置文件所适用的范围如下图:

${flink.dir}中默认不包含DailyRollingFileAppender的依赖,所以在使用DailyRollingFileAppender时还需要添加依赖apache-log4j-extras-1.2.17.jar到${flink.dir}/lib/目录,Flink Job的日志会输出到Yarn Container的日志目录下(由yarn-site.xml中的yarn.nodemanager.log-dirs指定),Container的启动脚本(可在YarnUI log中找到)示例:
// log.file 即日志输出目录
exec /bin/bash -c "$JAVA_HOME/bin/java -Xms1394m -Xmx1394m -XX:MaxDirectMemorySize=654m -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -Dlog.file=/home/hadoop/apache/hadoop/latest/logs/userlogs/application_1547994202702_0027/container_e02_1547994202702_0027_01_000002/taskmanager.log -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner --configDir . 1> /home/hadoop/apache/hadoop/latest/logs/userlogs/application_1547994202702_0027/container_e02_1547994202702_0027_01_000002/taskmanager.out 2> /home/hadoop/apache/hadoop/latest/logs/userlogs/application_1547994202702_0027/container_e02_1547994202702_0027_01_000002/taskmanager.err"
运行中的FlinkOnYarn Job日志查看:
直接通过YarnUI界面查看每个Container的日志输出,如下图:
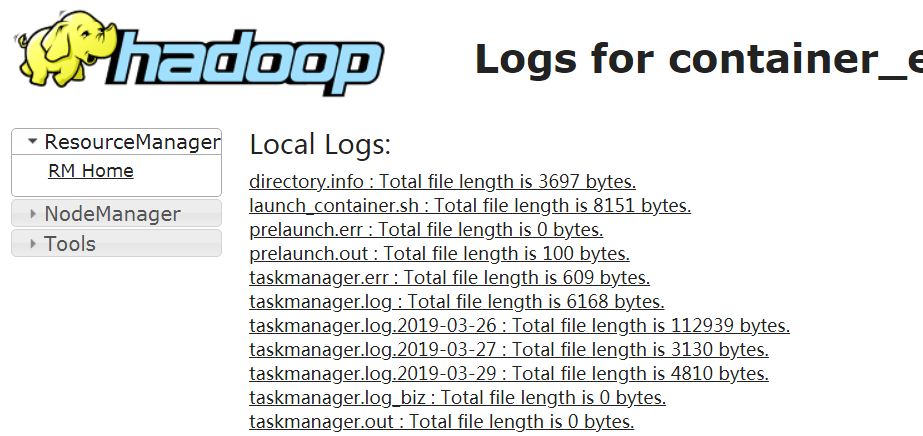
在container所在节点的对应目录下通过tail, less等shell命令查看日志文件,如下图:
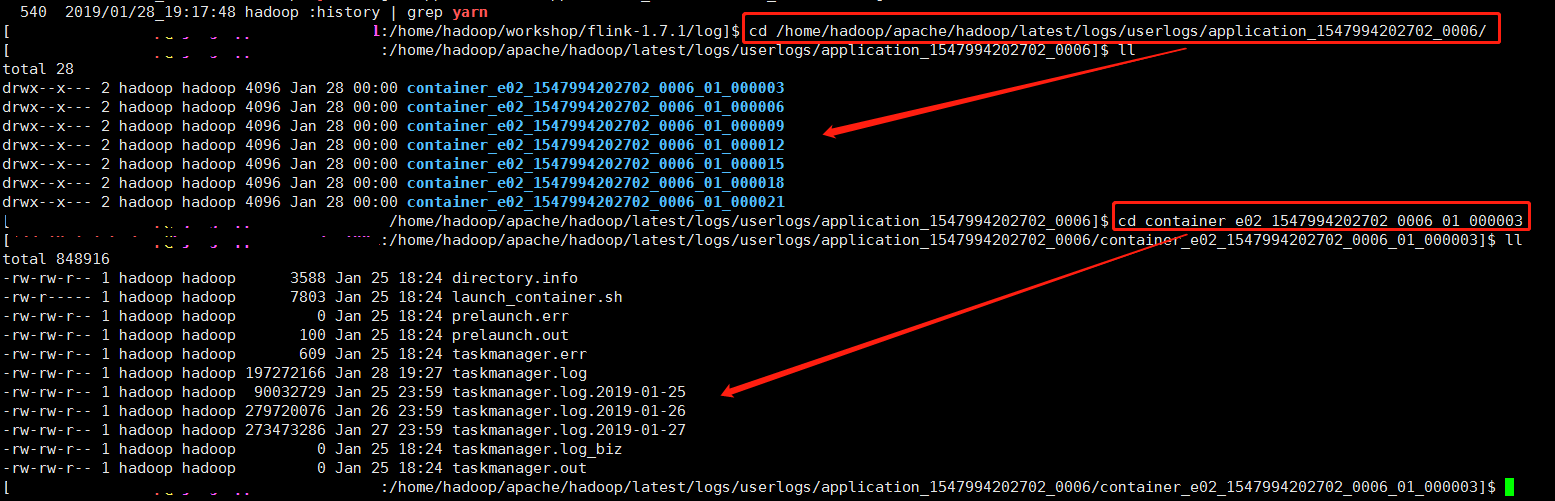
在hadoop配置enable log aggregation时,可以通过yarn logs -applicationId ${application_id}获取log;
已完成的FlinkOnYarn Job日志查看:
在配置hadoop log aggregation时,可以通过yarn logs -applicationId ${application_id}获取log;
注: Spark中HistoryServer支持用户从YarnUI中查看已完成Job的日志等,但Flink中的HistoryServer在OnYarn下不可用,留下问题后续解决;
Prometheus监控
FlinkUI的指标监控使用起来不够方便,同时在Job比较大时往FlinkUI上添加监控指标时卡顿现象非常明显,需要选择一个更好的Job监控工具来完成Job的监控任务,Prometheus是一个很好的选择;具体说明可参考官方Doc:https://ci.apache.org/projects/flink/flink-docs-release-1.7/monitoring/metrics.html;
Flink从1.4版本开始支持Prometheus监控PrometheusReporter,在Flink1.6时有加入了PrometheusPushGatewayReporter的功能;
PrometheusReporter是Prometheus被动通过Http请求Flink集群以获取指标数据;
PrometheusPushGatewayReporter是Flink主动将指标推送到Gateway,Prometheus从Gateway获取指标数据;
OnYarn下Flink端开启Prometheus监控的配置:
// Flink可以同时定义多个reportor,本示例定义了jmx和prometheus两种reportor
// JMX用RMI,Prom用Http
metrics.reporters: my_jmx_reporter,prom
metrics.reporter.my_jmx_reporter.class: org.apache.flink.metrics.jmx.JMXReporter
metrics.reporter.my_jmx_reporter.port: 9020-9045
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
metrics.reporter.prom.port: 9250-9275
当Job分配到Yarn Container启动JobManager/TaskManager的过程中会实例化metrics.reporter.xxx.class配置的类,启动监控服务;
PrometheusReporter是通过暴漏Http地址来提供监控指标访问功能的,在每个JobManager/TaskManager启动的过程中都会实例化一个PrometheusReporter对象,并启动HttpServer服务绑定到一个端口上
(metrics.reporter.prom.port配置的区间从小到大第一个未占用的端口);因此metrics.reporter.prom.port配置的区间可允许的最大端口数必须大于等于一台机器最大可启动的Container数量,
否则会有监控服务启动失败的报错,如下:
报错:
2019-03-12 20:44:39,623 INFO org.apache.flink.runtime.metrics.MetricRegistryImpl - Configuring prom with {port=9250, class=org.apache.flink.metrics.prometheus.PrometheusReporter}.
2019-03-12 20:44:39,627 ERROR org.apache.flink.runtime.metrics.MetricRegistryImpl - Could not instantiate metrics reporter prom. Metrics might not be exposed/reported.
java.lang.RuntimeException: Could not start PrometheusReporter HTTP server on any configured port. Ports: 9250
at org.apache.flink.metrics.prometheus.PrometheusReporter.open(PrometheusReporter.java:70)
at org.apache.flink.runtime.metrics.MetricRegistryImpl.<init>(MetricRegistryImpl.java:153)
at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.<init>(TaskManagerRunner.java:137)
at org.apache.flink.runtime.taskexecutor.TaskManagerRunner.runTaskManager(TaskManagerRunner.java:330)
at org.apache.flink.runtime.taskexecutor.TaskManagerRunner$1.call(TaskManagerRunner.java:301)
at org.apache.flink.runtime.taskexecutor.TaskManagerRunner$1.call(TaskManagerRunner.java:298)
总结
本文简单总结了Flink使用过程中遇到的几个重要的问题,taskmanager.network.numberOfBuffers配置的问题有在stackoverflow, FlinkCommunity问过,但没得到较为准确的答案,最终通过gg文档&源码才逐渐理解,源码&Google的重要性不言而喻!
参考
- https://cwiki.apache.org/confluence/display/FLINK/Data+exchange+between+tasks
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/flinkDev/building.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/stream/state/custom_serialization.html
- https://ci.apache.org/projects/flink/flink-docs-master/dev/types_serialization.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/monitoring/debugging_classloading.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/flinkDev/building.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/monitoring/logging.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/monitoring/historyserver.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/monitoring/debugging_classloading.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/monitoring/metrics.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.7/dev/types_serialization.html